Analyser les performances
29 minutes à lire
Objectifs – Vous ne pouvez agir sans savoir. L’amélioration de performance doit se baser sur les faits, et les améliorations doivent être vérifiables ensuite. Les outils de monitoring et de trace vous donnent les outils indispensables à la compréhension du problème, donc à sa résolution. Ce chapitre présente les outils d’analyse à votre disposition.
SQL Server Management Studio
Dans SSMS, vous avez plusieurs outils pour analyser la performance de vos requêtes SQL. Un plan d’exécution graphique est affichable, nous en parlerons en détail section 8.1. Nous présentons ici les autres options.
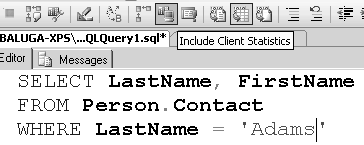
Les statistiques du client sont des chiffres collectés par la bibliothèque d’accès aux données, et qui sont visibles en tableau dans SSMS. Elles vous permettent de vous faire une idée des instructions exécutées, du nombre de transactions, et surtout du volume de données qui a transité jusqu’à vous pour un batch de requêtes. Lorsque vous activez cette fonctionnalité, à l’aide du bouton de la barre d’outils illustré sur la figure 5.1, vous obtenez un nouvel onglet de résultat.
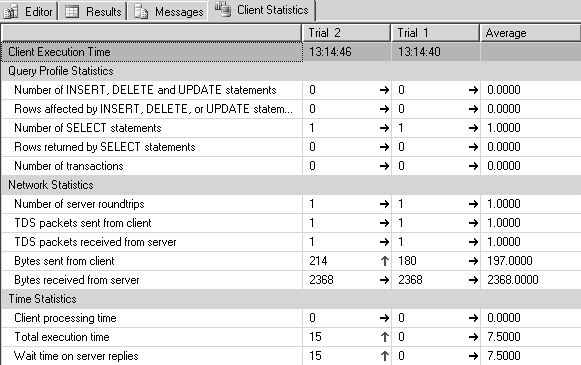
Si vous exécutez le même batch plusieurs fois, vous obtenez un tableau comparatif des statistiques d’exécution, avec des indicateurs fléchés vous indiquant la tendance par rapport à l’exécution précédente. Exemple en figure 5.2.
Vous pouvez réinitialiser ces statistiques à l’aide de la commande « Reset Client Statistics » du menu Query.
L’option de session SET STATISTICS TIME ON retourne les statistiques de temps d’exécution, visibles dans l’onglet « Messages ».
Voici un exemple de retour :
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 22 ms.
Les statistiques de temps ne sont pas des mesures précises : elles changent à tout moment, selon la charge du serveur, du réseau et les verrous. Néanmoins cela vous donne une idée du temps de compilation, et la différence entre le temps CPU et le temps total (elapsed) vous indique des attentes sur les verrous, les entrées/sorties et le réseau.
L’option de session SET STATISTICS IO ON retourne les statistiques d’entrées/sorties fournies par le moteur SQL Server, en unité de pages. Elles sont une mesure plus précise, car elles indiquent de façon constante le vrai coût d’une requête pour le moteur de stockage.
Exemple de retour :
Table 'Contact'. Scan count 1, logical reads 1276, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob
read-ahead reads 0.
Vous voyez le nombre de scan de table ou d’index (mal traduit dans la version française par « analyse »), le nombre de reads logiques, de reads physiques (les appels aux pages non trouvées dans le buffer), les lectures anticipées (SQL Server peut appeler à l’avance des pages qu’il prévoir utiliser plus tard dans l’exécution de la requête), et les lectures de pages LOB (objets larges et row overflow).
Lire les Résultats
SET STATISTICS TIME, IO ON
SET LANGUAGE 'us_english'
SET NOCOUNT ON
Les résultats de SET STATISTICS IO ON, comme le texte des messages d’erreur, est récupérable par trace, dans l’événement Errors and Warnings : User Error Messages.
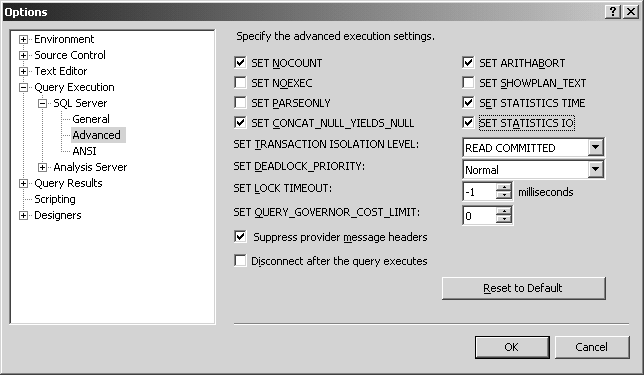
Vous pouvez activer ces options pour toutes les sessions en les activant automatiquement dans les options SSMS, comme illustré en figure 5.3.
Sql trace et Le profiler
SQL Trace est une technologie intégrée au moteur SQL Server, qui permet de fournir à un client le détail de quantité d’événements se produisant dans les différentes parties de SQL Server.
On peut comparer SQL Trace à un débogueur. Devant un programme complexe, organisé en multiples classes et modules, un développeur qui doit identifier la cause d’un problème à partir d’un rapport de bug, n’a qu’une méthode efficace à disposition : reproduire le problème en suivant pas à pas le comportement du code à l’aide de son outil de déboguage, observant les valeurs attribuées aux variables, les changements d’état des classes, l’itération des boucles.
Sans cette capacité à entrer dans les opérations du code, à observer finement ce qui se passe, le travail de déboguage serait réduit à une recherche fastidieuse faite d’essais, d’instructions PRINT, de lecture attentive de code.
Un serveur SQL ajoute des niveaux de complexité supplémentaires, qui rendent la méthode expérimentale cauchemardesque : on peut rarement deviner à la simple lecture d’une requête quel en est le plan d’exécution, c’est-à-dire la stratégie que va appliquer SQL Server pour en assurer l’exécution optimale.
Pour le savoir, il faudrait faire soi-même tout le travail de l’optimiseur : inspecter les tables, lister les index et leurs statistiques, estimer le nombre de lignes impactées, essayer plusieurs stratégies, estimer leur coût…
Il est donc pratiquement impossible de deviner ce qui va précisément se passer.
De plus, l’exécution concurrentielle des requêtes rend les performances dépendantes du contexte : charge de travail des processeurs, attente sur des verrous, performance des tables temporaires…
Sans SQL trace, SQL Server serait une boîte noire, nous n’aurions aucun moyen d’identifier précisément les raisons d’un ralentissement soudain, ou d’une charge excessive du système.
Dans chaque instance de SQL Server, un sous-système nommé le contrôleur de trace (trace controller) est responsable de la collecte d’événements produits par des fournisseurs propres à chaque partie du moteur, et à l’envoi de ces événements aux clients inscrits. Ces fournisseurs ne sont activés que si au moins un client écoute activement un des événements qu’ils produisent. Le contrôleur de trace distribue ensuite les résultats à des fournisseurs d’entrées/sorties (trace I/O providers), ce qui permet à une trace d’être directement sauvée dans un fichier binaire par le serveur, ou envoyée à un client, comme le profiler.
Le profiler, incorrectement traduit dans certaines versions de SQL Server par « gestionnaire de profils » est donc en réalité un programme client qui affiche les informations d’une trace SQL. Il est l’outil incontournable de l’optimisation. Il vous permet de suivre le comportement de votre serveur, en interceptant tous les événements envoyés par SQL Trace, dont bien entendu les requêtes SQL, accompagnés de précieuses informations sur leur impact et leur exécution. Il est important de bien le connaître et nous allons donc en détailler les fonctionnalités.
Le profiler peut afficher en temps réel un flux de trace SQL, mais aussi charger une trace enregistrée préalablement dans un fichier de trace ou dans une table SQL. Il peut sauvegarder une trace dans ces deux destinations, et également rejouer une trace sur un serveur SQL, c’est-à-dire exécuter à nouveau toutes les requêtes SQL contenues dans la trace, ce qui est fort utile pour faire un test de charge, par exemple.
Vous en trouvez l’icône dans le menu de SQL Server, dossier Performances tools (outils de performance). Lorsque vous créez une nouvelle session, une fenêtre à deux onglets vous permet de sélectionner un certain nombre d’options.
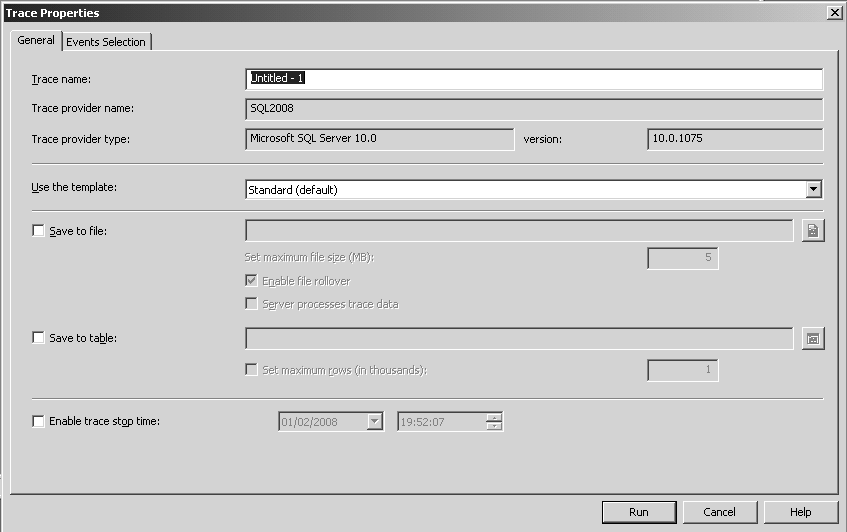
Dans l’onglet General, vous pouvez nommer votre trace, ce qui est utile lorsque vous en créez plusieurs (le profiler est une application MDI (Multiple Documents Interface) qui peut exécuter plusieurs trace en même temps), et pour prédéfinir le nom du fichier lorsque vous sauvegarderez la trace. En grisé, vous pouvez voir le nom et la version du fournisseur SQL trace. Les profilers 2005 et 2008 peuvent lancer des traces sur des versions antérieures de SQL Server. Dans ce cas, les événements et colonnes à disposition reflètent les possibilités de la version du serveur.
Vous pouvez baser votre nouvelle trace sur un modèle (template), c’est-à-dire un squelette de trace comprenant toutes les propriétés choisies dans le profiler, y compris les choix d’événements, les colonnes et les filtres. Vous pouvez utiliser le choix de modèles prédéfini, mais aussi créer vos modèles personnalisés en sauvant votre trace comme nouveau modèle.
Vous pouvez choisir de visualiser votre trace en temps réel, en laissant les événements se dérouler devant vos yeux, et vous pouvez aussi sauvegarder cette trace dans un fichier binaire ou XML, ou dans une table SQL Server, au fur et à mesure de son exécution en indiquant la destination dans cet onglet, ou ensuite, à l’aide de la commande Save As… du menu File.
L’écriture à la volée d’une trace volumineuse dans une table peut être très pénalisante pour le serveur SQL. Préférez l’enregistrement en fichier binaire. Vous aurez ensuite la possibilité de la recharger dans le profiler et de le sauvegarder dans une table SQL au besoin. Si vous choisissez néanmoins d’écrire directement dans une table, faites-le de préférence sur un serveur différent de celui tracé.
Vous pouvez indiquer une taille maximale du fichier de trace et segmenter vos fichiers de trace avec l’option enable file rollover.
Lorsque la taille maximale indiquée est atteinte, un nouveau fichier numéroté est créé.
Si votre fichier est nommé matrace.trc, les suivants seront matrace_1.trc, matrace_2.trc, et ainsi de suite.
Si vous décochez l’option enable file rollover, l’enregistrement s’arrêtera lorsque la taille sera atteinte. La visualisation en temps réel, elle, se poursuivra. Pensez à l’affichage dans le profiler et à l’enregistrement de la trace comme des redirections séparées d’une même trace. Si vous choisissez un enregistrement dans une table, vous pouvez limiter le nombre de milliers de lignes à y écrire, avec l’option Set maximum rows.
Si votre objectif n’est pas d’analyser en temps réel l’activité de votre serveur, mais de laisser tourner votre trace pour, par exemple, établir une baseline, vous pouvez indiquer un arrêt automatique de la trace avec l’option Enable trace stop time. Nous verrons qu’il est préférable dans ce cas de lancer une trace directement sur le serveur.
L’onglet « Events Selection » est le cœur du profiler, il vous permet de choisir les informations retournées : événements, colonnes, et filtres.
Les classes d’événements récupérables sont groupés en catégories. Elles publient un certain nombre d’informations présentées dans des colonnes. Toutes les colonnes ne sont pas alimentées pour chaque classe, vous trouverez les colonnes utiles dans les BOL, sous l’entrée correspondant à l’événement.
Par défaut, et pour simplifier l’affichage, cet onglet ne vous montre que les événements sélectionnées dans le modèle choisi. Pour faire votre sélection parmi tous les événements disponibles, cochez Show all events. Vous obtenez ainsi une liste des catégories et des classes d’événements associés. Les catégories sont reproduites dans le tableau 5.1.
Tableau 5.1 – Catégories d’événements de trace
| Catégorie | Description |
|---|---|
| Broker | Événements Service Broker. |
| CLR | Exécution des objets .NET intégrés à SQL Server. |
| Cursors | Opérations de curseurs T-SQL. |
| Database | Changement de taille des fichiers de base de données, et événements de mirroring. |
| Depreciation | Alertes d’utilisation de fonctionnalités obsolètes. |
| Errors and Warnings | Avertissements et exceptions diverses. |
| Full Text | Alimentation des index de texte intégral (FTS). |
| Locks | Acquisition, escalade, libération et timeout de verrous (Génère une activité importante), et alertes de verrous mortels (deadlocks). |
| OLEDB | Appels OLEDB effectués par SQL Server en tant que client : par exemple lors de requêtes distribuées sur des serveurs liés. |
| Objects | Création, modification et suppression d’objets de base (Ordres DDL CREATE, ALTER, DROP) |
| Performance | Informations diverses de performance, notamment les plans d’exécution d’ordres SQL. |
| Progress Report | Information d’avancement d’une opération d’indexation en ligne (online indexing). Voir chapitre 6. |
| Query Notifications | Événements générés par la fonctionnalité Query Notifications. Voir encadré en fin de chapitre 8. |
| Scans | Scans de tables et d’index. |
| Security Audit | Ouvertures et fermeture de sessions, échec de connexion et divers audit de privilèges et d’exécution de commandes (BACKUP, DBCC…). |
| Server | Principalement, changement de mémoire de l’instance. |
| Sessions | Sessions ouvertes au moment du démarrage de la trace. |
| Stored Procedures | Exécution de procédures stockées (T-SQL seulement), et détail des ordres exécutés dans la procédure. |
| TSQL | Ordres SQL envoyés au serveur en batch. Aussi instructions XQuery. |
| Transactions | Détail de la gestion des transactions. |
| User Configurable | Événements utilisateur. |
Certaines classes d’événements sont très spécifiques et ne vous seront que d’une utilité occasionnelle. Elles sont toutes décrites en détail dans les BOL, sous l’entrée « SQL Server Event Class Reference », avec, pour chaque événement, les colonnes retournées. Nous présentons dans cet ouvrage les événements importants pour l’analyse de performance, ceux que vous serez amenés à utiliser souvent.
De même, si nous nous concentrons sur les performances, quelques colonnes seulement nous sont utiles. Vous trouverez la liste des colonnes disponible dans les BOL, sous l’entrée « Describing Events by Using Data Columns ». Nous distinguerons les colonnes contenant des valeurs indiquant les performances, de celles affichant des informations sur l’événement, et qui vous permettront par exemple de grouper ou de filtrer les résultats.
Vous pouvez générer vos propres événements dans votre code SQL, à l’aide de la procédure stockée sp_trace_generateevent.
Vous pouvez passer dix événements différents, numérotés en interne de 82 à 91 (ce sont donc ces ID que vous passez en paramètre à la procédure sp_trace_generateevent), et que vous retrouvez dans le profiler sous User Configurable : UserConfigurable:0 à UserConfigurable:9.
Voici un exemple de déclenchement d’événement :
DECLARE @userdata varbinary(8000)
SET @userdata = CAST('c''est moi' as varbinary(8000))
EXEC sys.sp_trace_generateevent
@event_class = 82,
@userinfo = N'J''existe !!',
@userdata = @userdata
Cet événement sera visible comme UserConfigurable:0.
Le contenu de @userinfo sera affiché dans la colonne TextData et le contenu de @userdata dans la colonne BinaryData.
Événements
Les événements les plus utiles sont :
Database\Data File Auto Grow – une augmentation automatique de la taille d’un fichier de données s’est produite. La base de données affectée est visible dans la colonne
DatabaseID;Database\Log File Auto Grow – une augmentation automatique de la taille d’un fichier de journal s’est produite. La base de données affectée est visible dans la colonne
DatabaseID;Errors And Warnings\Attention – se déclenche lorsqu’un client est déconnecté brusquement ;
Errors And Warnings\Exception – Erreurs retournées par SQL Server au client, plus de détails plus loin ;
Errors And Warnings\Execution Warnings – avertissements déclenchés par SQL Server à l’exécution de la requête ;
Errors And Warnings\Missing Column Statistics – type spécial d’avertissement : il manque des statistiques sur une colonnes. Voir la section 6.4 ;
Errors And Warnings\Sort Warnings – avertissement sur une opération de tri qui n’a pu être complètement exécutée en mémoire, et a donc « bavé » dans tempdb.
Reportez-vous à la section 8.1.2 ;Locks – événements sur les verrous. Les événement de pose de verrous sont trop fréquents pour être utiles. Les événements de timeout vous permettent de tracer des attentes trop longues annulées par une valeur de
LOCK_TIMEOUTde la session (voir section 7.2). Les événements de deadlock seront détaillés dans la section 7.5.2) ;Performance\Auto Stats – création ou mise à jour automatique de statistiques, voir section 6.4 ;
Performance\ShowPlan… – affichage du plan d’exécution, voir section 8.1 ;
Server\Server Memory Change – modification de la mémoire vive utilisée par SQL Server, peut être utile pour tracer une pression mémoire, en alerte de l’agent SQL, par exemple ;
Stored Procedures\RPC:Completed – un appel RPC (Remote Procedure Call : appel de procédure depuis un client, avec la syntaxe
CALL, ou un objetStoredProcedurede la bibliothèque cliente). Contient les statistiques d’exécution (durée, lectures, …)Stored Procedures\SP:Completed – fin de l’exécution d’une procédure stockée. Contient les statistiques d’exécution (durée, lectures, …)
Stored Procedures\SP:Recompile – recompilation d’une procédure ou d’une partie de celle-ci, voir la section 9.1 ;
Stored Procedures\SP:StmtCompleted – analyse de l’exécution de chaque instruction d’une procédure stockée. Contient les statistiques d’exécution (durée, lectures, …)
TSQL\SQL:BatchCompleted – fin de l’exécution d’un batch de requêtes. Contient les statistiques d’exécution (durée, lectures, …)
TSQL\SQL:StmtCompleted – Fin de l’exécution d’une instruction dans un batch. Contient les statistiques d’exécution (durée, lectures, …)
Colonnes
Les colonnes peuvent servir à filter ou regrouper vos événements. Vous pouvez créer de multiples filtres. Sans ces filtres, une trace en production est pratiquement illisible : à peine l’avez-vous démarrée, que des milliers, voir des dizaines de milliers d’événements sont déjà tracés. Filtrer est non seulement indispensable pour la visibilité des informations, mais pour diminuer l’impact de la trace. En effet, le filtre sera appliqué du côté du serveur, et allègera donc la trace.
Pour filtrer vous pouvez soit cliquer sur le bouton « Column filters… » de l’onglet « Events Selection… » de la fenêtre de propriétés de la trace, soit en cliquant directement sur l’en-tête d’une colonne dans cette même fenêtre. Une boîte de dialogue de filtre (figure 5.5) s’ouvre.
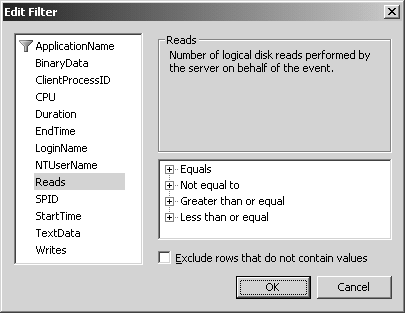
Vous pouvez accumuler les filtres sur une même colonne, avec différents opérateurs. Les colonnes filtrées montrent une icône d’entonnoir. Avant SQL Server 2005, les événements qui ne retournaient rien dans la colonne filtrée étaient affichés quand même, ce qui était assez peu pratique. Depuis SQL Server 2005, l’option « Exclude rows that do no contain values » permet de filtrer ces événements. Pensez-y, elle n’est pas sélectionnée par défaut.
Quelques idées de filtre : filtre sur un SPID particulier pour tracer une seule session, filtre sur une ApplicationName pour analyser ce que fait une application cliente, filtre sur TextData pour trouver les instructions SQL qui s’appliquent à un objet.
Dans ce cas, la syntaxe du LIKE est la même qu’en SQL : le caractère % (pourcent) remplace une chaîne de caractères.
Pour une trace destinée à détecter les requêtes les plus coûteuse, un filtre sur le nombre de reads (opérateur égal ou plus grand que) est la meilleure méthode : les reads ne varient pas d’un appel à un autre à données égales, et plus le nombre de reads est important, plus l’instruction est lourde, non seulement pour sa propre exécution, mais aussi, à travers les ressources qu’elle consomme et les verrous qu’elle pose peut-être, pour toutes les autres s’exécutant simultanément.
Vous pouvez aussi grouper à l’affichage, par colonne(s). Cela vous permet d’obtenir une vue non plus chronologique, mais dans un ordre qui vous siet mieux. Dans ce cas, la lecture peut être moins intuitive. Cliquez sur le bouton Organize columns… (ou clic droit sur les en-têtes de colonne, et commande organize columns…). Dans la fenêtre qui s’ouvre, les bouton Up et Down permettre d’organiser l’ordre des colonnes. Un Up jusqu’au nœud Groups crée un regroupement.
Sur la figure 5.6, vous voyez un regroupement par ApplicationName, puis SPID.
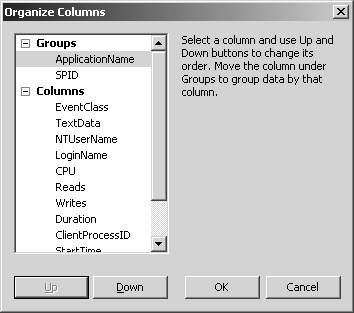
L’affichage en temps réel triera les événements par ces colonnes de regroupement, vous n’aurez donc plus une vision strictement chronologique. De même, ces colonnes seront toujours visibles à gauche, même si vous défilez sur la droite pour afficher plus de colonnes. Si vous ne sélectionnez qu’une seule colonne de groupement, vous obtiendrez une vision arborescente, réduite par défaut.
Colonnes utiles aux performances
CPU – indique le temps processeur consommé par l’événement, en millisecondes. Si ce temps processeur est supérieur à la valeur de
Duration, votre requête a été parallélisée sur plusieurs CPUs ;Duration – indique la durée totale d’exécution de l’événement, y compris le temps d’envoi du résultat au client ;
Reads – indique le nombre de pages lues par la requête. Il s’agit bien d’unités de pages de base de données, de 8 Ko chacune. Pour obtenir le nombre d’octets lus, vous pouvez multiplier cette valeur par 8192. Notez que vous ne pouvez pas obtenir le détail séparé des pages lues du buffer et récupérées du disque qui forment ce nombre total de reads. Cette information n’est disponible que dans les statistiques récupérées en exécutant une requête avec l’option de session
SET STATISTICS IO ONdans un client comme SSMS, ou en corrélant vos requêtes avec des compteurs du moniteur de performances ;RowCounts – nombre total de lignes affectées (lues, insérées, modifiées, supprimées) par l’ordre, le batch, ou la procédure ;
TextData – Texte de l’ordre SQL exécuté ;
Writes – nombre de pages de données écrites.
Ces colonnes indiquant des mesures chiffrées de l’exécution d’ordres SQL, elles ne sont bien entendu retournées que par les événements déclenchés à la fin d’un ordre. Dans les couples d’événements tels que SQL:BatchStarting et SQL:BatchCompleted ou SP:Starting et SP:Completed, c’est l’événement Completed qui vous intéressera. L’événement Starting ne sera utile que si vous désirez observer ce qui se passe entre le début et la fin de l’ordre (par exemple à l’aide de l’événement SP:StmtCompleted qui détaille l’exécution des parties d’une procédure stockée), ou si, à cause d’une exception, votre ordre ne se termine pas correctement.
Attention
les colonnesCPUetDurationenregistrent en interne des durées en microsecondes (un millionième de seconde, 10 puissance -6). Elles sont affichées dans le profiler en millisecondes, comme pour les versions précédentes de SQL Server, mais lorsque vous travaillez hors du profiler, par exemple dans un trace sauvegardée dans une table, ces valeurs seront en microsecondes. Vous devez donc diviser par 1000 pour obtenir des millisecondes.
D’autres colonnes sont indicatives, et utiles également pour filtrer vos événements :
ApplicationName – nom de l’application cliente, passée dans la chaîne de connexion. Par exemple SSMS se fait connaître sous le nom Microsoft SQL Server Management Studio. Si vous développez des applications clients « maison », il est utile de le spécifier, soit dans la chaîne de connexion (en y ajoutant
Application Name=), soit à l’aide de la propriété idoine de votre bibliothèque client (par exemple la propriétéApplicationNamede l’objetSqlConnectionStringBuilderen ADO.NET). Cela vous permettra de savoir d’où viennent vos requêtes, et d’afficher les événements provenant d’une application seulement. Les développeurs peuvent aussi générer cetApplicationNameen y incluant le numéro de version de leur produit. Cela rend aisé la vérification des mises à jour sur tous les clients, et cela permet, par exemple, de créer un déclencheur DDL qui vérifie cette valeur à l’aide de la fonction systèmeAPP_NAME()et interdit l’ouverture de session si la version du client n’est pas suffisante ;DatabaseID – l’identifiant de base de données courante, utile pour n’afficher que les requêtes effectuées dans une base de données. Vous pouvez trouver cet Id dans la colonne database_id de la vue système
sys.databases, ou à l’aide de la fonctionDB_ID(). Notez qu’il s’agit du contexte de base dans lequel l’ordre est exécuté, et non la localisation des objets touchés. Si vous requêtez la tableAdventureWorks.Person.Contactdepuis la basemaster, en utilisant comme ici le nommage completbase.schéma.objet, votreDatabaseIDsera 1 (valeur toujours attribuée à la basemaster) ;DatabaseName – nom de la base de données en toutes lettres. Plus intuitif que
DatabaseID;GroupID – En SQL Server 2008, identifiant du groupe de ressources du gouverneur de ressources. Voir la section 4.5 ;
HostName – nom de la machine cliente qui a ouvert la session. Correspondant au résultat de la fonction niladique
HOST_NAME();IndexId – identifiant de l’index. Correspond à la colonne
index_idde la vue systèmesys.indexes. Utile pour tracer les scans ;IsSystem – indique si l’événement est déclenché par une session système. Valeur
0s’il s’agit d’une session utilisateur. Très utile pour filtrer les événements ;LineNumber – contient le numéro de ligne de l’ordre, dans le batch ou dans la procédure stockée. Sur les erreurs, indique la ligne sur laquelle elle s’est produite ;
LoginName – contient le nom de la connexion (login) qui a ouvert la session. Nom complet avec domaine en cas de connexion Windows intégrée (le nom simple sera alors récupérable dans la colonne
NTUserName) ;ObjectID – identifiant de l’objet. Correspond à la colonne
object_iddes vues systèmessys.objectsousys.tables. Utile pour tracer les scans ;SPID – identifiant de session attribué par SQL Server. Correspond à la valeur récupéré par la variable système
@@SPID. Utile pour filtrer une trace sur une seule session. Attention cependant : dès la session fermée, ce même numéro peut être réattribué par SQL Server à une nouvelle session.
Détection d’exceptions
Les événements de la catégorie Errors and Warnings tracent les erreurs et exceptions générées par SQL Server. C’est un bon moyen de surveiller votre serveur. Parfois, certaines applications clientes provoquent des erreurs qui ne sont pas récupérées dans leur code, ce qui fait que ces erreurs restent invisibles.
Parfois également, des erreurs se produisent, et les utilisateurs pressent la touche entrée sur des messages difficile à comprendre, sans appeler le support informatique. Ou, lorsque vous définissez vos propres erreurs, vous aimeriez savoir quand elles se déclenchent.
La meilleure manière de récupérer une erreur occasionnelle lorsque vous vous y attendez, est de définir une alerte dans l’agent SQL.
Vous pouvez vous faire notifier par l’agent du déclenchement de toute erreur, par sa gravité, son numéro ou un texte qu’elle contient.
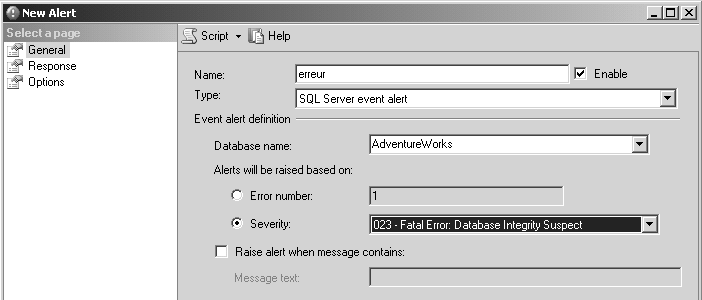
La programmation d’une alerte est hors du sujet de ce livre, nous vous montrons simplement, sur la figure 5.7, un exemple d’alerte déclenchée sur une erreur de gravité 23, déclenchée dans le contexte de la base AdventureWorks.
La réponse à cette alerte peut être l’envoi d’une notification par e-mail ou NET SEND, ou l’activation d’un travail de l’agent.
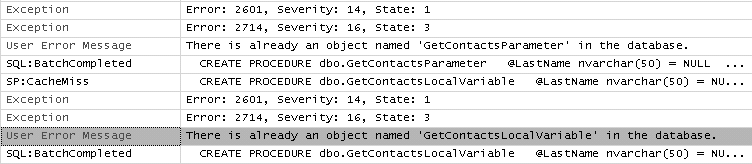
Vous pouvez aussi, de temps en temps, tracer votre serveur à l’aide du profiler, pour vous assurer qu’aucune erreur ne passe indétectée. Les erreurs générées par SQL Server et renvoyées à la session cliente, sont appelées exceptions. Cela peut être l’information qu’un objet déclaré dans le code n’existe pas, la violation d’une contrainte, etc.
Vous récupérez le numéro d’erreur dans l’événement Exceptions, et le message d’erreur tel qu’il est envoyé au client, dans l’événement User Error Message. Vous voyez sur la figure 5.8 un exemple de trace d’erreur. La signification des numéros d’erreur est indiquée dans les BOL.
Utiliser le résultat de la trace
Une trace sauvegardée dans un fichier ou dans une table peut être ouverte à l’aide du profiler (menu File / Open / Trace File… ou Trace Table…). Les lignes peuvent être filtrées et groupées comme sur une trace en temps réel. Pour réaliser une analyse approfondie des résultats de la trace, la meilleure solution est d’enregistrer ce résultat dans une table SQL.
Pour ce faire, rechargez le fichier de trace dans le profiler, puis sauvez le résultat dans une table à l’aide de la commande File / Save As / Trace Table …
SELECT * INTO dbo.matrace
FROM sys.fn_trace_gettable('c:\temp\matrace.trc', default);
Lit les fichiers de trace dont le nom de base est matrace.trc et les insère dans la table dbo.matrace.
La valeur 'default' indique que tous les fichiers de rollover présents doivent être insérés.
Ensuite, rien n’est plus facile que de lancer des requêtes sur la table pour obtenir les informations désirées. Voici par exemple une requête listant par ordre décroissant les requêtes les plus coûteuses :
SELECT
CAST(TextData as varchar(8000)) as TextData,
COUNT(*) as Executions,
AVG(reads) as MoyenneReads,
AVG(CPU) as MoyenneCPU,
AVG(Duration) / 1000 as MoyenneDurationMillisecondes
FROM dbo.matrace
WHERE EventClass IN (
SELECT trace_event_id
FROM sys.trace_events
WHERE name LIKE 'S%Completed')
GROUP BY CAST(TextData as varchar(8000))
ORDER BY MoyenneReads DESC, MoyenneCPU DESC;
Pour ne prendre que les requêtes, nous cherchons dans la vue sys.trace_events les événements qui commencent par 'S' (SQL ou SP) et qui se terminent par 'Completed'.
Rejouer une trace
Elle peut être rejouée, c’est-à-dire que les événements peuvent être réexécutés contre un serveur SQL, si les événements contenus dans la trace sont rejouables. Pour créer une trace rejouable, le plus simple est d’utiliser le modèle TSQL_Replay, qui ajoute tous les événements nécessaires à une trace entièrement rejouable.
Lorsque vous ouvrez une trace enregistrée, un menu Replay est ajouté, ainsi qu’une barre d’outils, comme montré en figure 5.9.

Vous pouvez poser un point d’arrêt sur une ligne d’événement (touche F9), faire du pas à pas (F10), ou exécuter la trace jusqu’à la ligne sélectionnée (CTRL+F10). Lorsque vous lancez l’exécution, une fenêtre vous permet de choisir les options, disposés dans deux onglets.
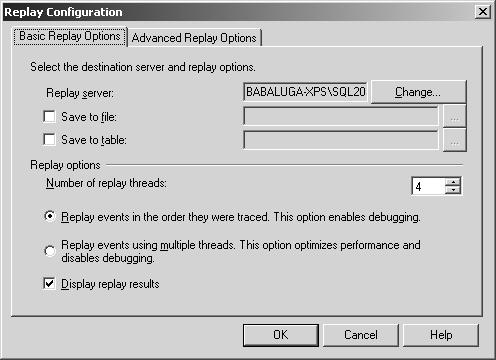
Dans le premier, reproduit sur la figure 5.10, vous indiquez si le résultat de l’exécution doit être enregistré dans un fichier ou une table.
Si décochés, il sera simplement affiché dans le profiler.
En utilisant les fonctionnalités de multi-threading, vous pouvez faire exécuter des instructions en parallèle.
Le profiler rejoue les événements sur plusieurs theads, groupés par SPID, dans l’ordre de la colonne EventSequence.
Vous reproduisez donc un environnement multi-utilisateurs. La trace est jouée plus vite, mais vous perdez les possibilités de déboguage (point d’arrêt, pas-à-pas, …)
Dans le premier, reproduit sur la figure 5.11, vous désactivez l’exécution d’instructions lancés par des sessions système pour ne garder que le comportement des sessions utilisateur. Vous pouvez n’exécuter que les instructions d’un SPID, en sachant que le même SPID peut être réutilisé par des sessions différentes, l’une après l’autre. Vous pouvez indiquer les intervalles de temps des événements de la trace qui doivent être rejoués. La partie Health Monitor permet de configurer un thread du Profiler pour tuer automatiquement les processus qui sont bloqués depuis un nombre défini de secondes. La valeur d’attente 0 signifie que le profiler ne tuera aucun processus bloqué. Nous traitons de la surveillance de processus bloqués dans la section 7.5.
Effectuer un test de charge
La capacité de rejouer des traces est intéressante pour faire un test de charge, sur un serveur de test ou sur un serveur final avant une mise en production, à l’aide d’une trace représentative de l’activité réel ou prévue du serveur.
Vous pouvez ouvrir plusieurs fois la même trace, et la rejouer à partir d’instances différentes du profiler, ou même de machines clientes différentes.
Cette approche pose un problème : il faut s’assurer que la trace ne comporte pas d’instructions qui ne peuvent être rejouées plus d’une fois, notamment des insertions explicites de valeurs vérifiées par des contraintes d’unicité.
Si c’est la cas, vous pouvez soit les retirer de la trace, soit les encapsuler dans des transactions que vous terminez en ROLLBACK.
Dans les deux cas, la gestion du replay devient plus, voire trop, contraignante.
Deuxième question : comment automatiser les replay ?
Le profiler (profiler90.exe en SQL Server 2005) comporte quelques paramètres d’appel en ligne de commande (faire profiler90.exe /? pour les voir), mais qui ne permettent pas de lancer une trace directement en replay.
Une solution peut être d’exporter le contenu des ordres SQL, par la commande File / Export / Extract SQL Server Events, qui génère un fichier de batches avec extension .sql.
Vous pouvez ensuite exécuter l’outil en ligne de commande sqlcmd.exe avec le paramètre -i :
sqlcmd.exe -E -S monserveur -i c:\temp\monbatch.sql
que vous pouvez lancer de multiples fois dans un script, dans une boucle par exemple.
Une autre solution consiste à utiliser les outils que l’équipe de support utilisateur de Microsoft a développés pour faciliter l’utilisation de traces pour les tests de charge.Ils sont packagés sous le nom de « RML Utilities for SQL Server », et peuvent être téléchargés sur le site de Microsoft (cherchez avec le nom du package). Ils nécessitent le framework .NET 3.5, qu’ils installent automatiquement si nécessaire.
Ces outils ne sont pas compatibles SQL Server 2008, notamment à cause des nouveaux types de données. Au moment de la rédaction de ce livre, la version 2008 est en développement, elle sera donc disponible tôt ou tard.
Diminuer l’impact de la trace
Comme nous l’avons dit, le profiler n’est qu’un client de la fonctionnalité serveur nommée SQL Trace. Le profiler est très utile en tant qu’outil d’optimisation, de débogage, et pour essayer, en temps réel, de découvrir la source d’un problème de performances.
Son défaut est qu’il utilise des ressources supplémentaires, soit du temps processeur lorsqu’il est lancé sur le serveur, soit de la bande passante réseau s’il tourne sur un poste client (ce qui est meilleur). Lorsque vous souhaitez planifier des traces, ou exécuter des traces de longue haleine, par exemple pour construire une baseline, ou pour identifier à travers une période représentative les requêtes les plus coûteuses, la solution la plus souple et la moins consommatrice de ressources, est de maintenir la trace à même SQL Server.
Pour cela, vous disposez de quelques procédures stockées système. Vous pouvez exporter la définition de la trace définie dans le profiler en ordres SQL, ce qui rend très facile la création de scripts de trace. Dans le profiler, choisissez dans le menu File la commande Export / Script Trace Definition, puis votre version de SQL Server.
Voici un exemple simplifié de script généré :
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
set @maxfilesize = 5
exec @rc = sp_trace_create @TraceID output, 0, N'InsertFileNameHere', @maxfilesize, NULL
if (@rc != 0) goto error
declare @on bit
set @on = 1
exec sp_trace_setevent @TraceID, 14, 1, @on
-- ...
-- Set the Filters
declare @intfilter int
declare @bigintfilter bigint
exec sp_trace_setfilter @TraceID, 10, 0, 7, N'SQL Server Profiler - 05b0b8f9-5048-4129-a0c1-9b7782ba8e6c'
-- Set the trace status to start
exec sp_trace_setstatus @TraceID, 1
-- display trace id for future references
select TraceID=@TraceID
sp_trace_create – crée une trace en retournant en paramètre
OUTPUTson identifiant numérique. Vous indiquez en paramètre le chemin du fichier dans lequel la trace sera enregistrée. Vous pouvez également indiquer la taille du fichier et le nombre maximum de fichiers de rollover, ainsi que la date et heure d’arrêt de la trace ;sp_trace_setevent – ajoute un événement à partir de son identifiant. Celui-ci peut être retoruvé dans la vue
sys.trace_events. Exemple de requête pour lister les événements :
SELECT tc.name as categorie, te.name as evenement, trace_event_id
FROM sys.trace_categories tc
JOIN sys.trace_events te ON tc.category_id = te.category_id
ORDER BY categorie, evenement;
sp_trace_setfilter – ajoute un filtre. Les paramètres indiquent l’id d’événement, un numérique indiquant un booléen pour organiser les filtres sur un même événement (AND ou OR entre les filtres), un numérique indiquant l’opérateur de comparaison, et la chaîne UNICODE à comparer ;
sp_trace_setstatus – démarre (
0), arrête (1) ou supprime (2) la trace. C’est ce qui vous donne le contrôle sur l’exécution de votre trace.
La vue système sys.traces vous permet de retrouver la liste des traces définies.
Lorsque vous avez une trace définie, vous pouvez planifier son exécution à l’aide de sp_trace_setstatus, par exemple dans des travaux de l’agent SQL.
Les traces système
SQL Server a deux traces spéciales, qu’il gère lui-même.
La première est appelée la trace par défaut (default trace).
Elle porte l’identifiant 1 et est activée par défaut.
Elle n’est pas listée par sys.traces, mais vous pouvez utiliser la fonction fn_trace_getinfo pour la voir :
SELECT * FROM fn_trace_getinfo(1);
Cette trace n’a pas de nom, elle est utilisée en interne pour alimenter des rapports, et peut être utilisée en cas de crash, pour aider à en identifier la cause.
Elle est écrite par défaut dans le répertoire de données, sous \LOG\log.trc (avec un nommage en rollover).
Elle est peu coûteuse et peut être conservée.
Si vous voulez la désactiver pour profiter des moindres moyens d’optimiser un serveur très chargé, vous pouvez changer l’option de serveur 'default trace enabled' à 0 :
EXEC sp_configure 'show advanced options' , 1
RECONFIGURE
EXEC sp_configure 'default trace enabled', 0
EXEC sp_configure 'show advanced options' , 0
RECONFIGURE
La seconde est une trace que vous pouvez activer, appelée la boîte noire (blackbox trace). Comme son nom l’indique, elle vous permet de conserver un historique récent des opérations réalisées sur le serveur, afin d’offrir des informations en cas de défaillance.
Elle est un peu plus lourde que la trace par défaut, car elle recueille plus d’événements.
Si vous ne voulez pas avoir une boîte noire permanente, vous pouvez l’activer en cas de suspicion de problème, ou pour déboguer des crash réguliers.
Pour cela, créez une trace avec sp_trace_create, et le paramètre @Options = 8 :
DECLARE @traceId int
EXEC sys.sp_trace_create @traceId OUTPUT, @Options = 8;
EXEC sys.sp_trace_setstatus @traceId, 1;
SELECT @traceId;
Vous pouvez modifier le chemin d’écriture du fichier, et la taille de celui-ci (5 Mo n’est pas toujours suffisant), avec les paramètres de sp_trace_create.
Pour vous assurer que la boîte noire tourne toujours, vous pouvez automatiser son démarrage en encapsulant son activation par sp_trace_setstatus dans une procédure stockée, et en faisant en sorte que cette procédure se lance au démarrage du service, à l’aide de la procédure sp_procoption :
EXEC sys.sp_procoption 'ma_procedure', 'STARTUP', 'ON';