Optimiser les objets et la structure de la base de données
66 minutes à lire
Objectifs
La toute première étape de l’optimisation est le design, l’architecture logique de vos bases de données. La qualité du modèle de données influencera tout le reste, et sera un atout ou un handicap pour toute la vie de la base. La modélisation est d’abord logique, faite d’entités et de relations, puis elle est physique, avec l’importance du choix des types de données pour chaque colonne – SQL étant un langage fortement typé. Enfin, une étape plus « physique » encore est de préparer soigneusement les structures du serveur : bases de données et tables.
Modélisation de la base de données
La plupart des progiciels maintiennent, sérialisent, des informations. Les outils de bureautique traitent évidemment des documents divers contenus dans des fichiers, les applications serveurs doivent souvent communiquer avec des systèmes hétérogènes et s’échangent des informations sous des formes standardisées : protocoles SMTP, HTTP, SOAP, …
C’est donc une spécificité des systèmes de gestion de bases de données de vous laisser organiser la structure des informations. La plupart des autres types de progiciels stockent leurs données de manière figée, parce que leurs besoins sont simplement différents. Cette liberté qui vous est laissée est un des éléments qui fait toute la puissance d’un SGBDR, mais elle a ses implications : d’une bonne structuration des données, dépendent aussi les performances de tout le système. Nous pouvons même dire que l’optimisation d’une base de données repose en premier lieu sur la qualité de son modèle de données. Il est illusoire d’attendre des miracles de requêtes SQL exécutés sur des données mal organisées. Pour cette raison, nous allons passer du temps sur ce sujet essentiel.
La modélisation se base sur la création préalable d’un Modèle Conceptuel de Données (MCD), une représentation de la structure d’entités et de relations indépendante de toute implémentation physique.
Le résultat pourra ensuite être appliqué à n’importe quel SGBDR, moyennant une adaptation à ses particularités d’implémentation, à travers un Modèle Physique de Données (MPD). La terminologie utilisée dans le MCD diffère légèrement de celle utilisée dans les implémentations physiques.
Pour mémoire, en voici un résumé dans le tableau 4.1.
Tableau 4.1 – Terminologie du modèle relationnel
| MCD | MPD | Définition |
|---|---|---|
| Type | Type | Le type de données d’un attribut. |
| Attribut, ou propriété | Colonne | Donnée élémentaire à l’intérieur d’une entité |
| Entité, ou relation | Table | Concept, objet, concert ou abstrait, qui représente un élément identifiable du système à modéliser. |
| Association | Relation | Un lien entre deux entités. |
| Tuple | Ligne | Une instance d’entité = une ligne dans une table. |
| Identifiant | Clé | Attribut ou ensemble d’attributs qui permet d’identifier uniquement chaque tuple d’une entité. |
| Cardinalité | Cardinalité | Décrit la nature d’une association en indiquant, à chaque extrémité, le nombre d’occurrences de tuples possible. |
La première étape de modélisation, l’étape conceptuelle, gagne à être simple et concrète. Votre modèle doit épouser la réalité. Une bonne façon de s’y prendre est de reproduire dans un schéma les phrases simples décrivant les états et les activités à modéliser. Les noms (sujet et complément) seront repris en entités, et le verbe sera l’association.
La cardinalité
la cardinalité représente le nombre d’occurrence, de tuples, de lignes. Dans un modèle, elle décrit le nombre d’occurrences possible de chaque côté d’une association. Par exemple, une association entre un contact et ses numéros de téléphones est en général une cardinalité de un-à-plusieurs, car on peut attribuer plusieurs numéros au même contact.
Mais cela pourrait être :
- un-à-un – un seul numéro de téléphone est permis par contact ;
- un-à-plusieurs – nous l’avons dit, plusieurs numéros par contact ;
- plusieurs-à-plusieurs – pour des numéros professionnel communs, au bureau, ils pourraient servir à joindre plusieurs personnes.
On ajoute souvent aux entités ayant des cardinalités « plusieurs » des discriminants, c’est-à-dire des attributs qui identifient le tuple parmi les autres. Par exemple, ce serait ici un type de numéro de téléphone : fixe, mobile, ou privé, professionnel. Ces discriminants pourront ensuite, dans l’implémentation physique, faire partie d’une clé unique si nécessaire.
Choisir ses clés
Une clé d’entité est un attribut, ou un ensemble d’attribut, qui permet d’identifier un tuple unique. C’est un concept essentiel de la modélisation, comme de l’implémentation physique relationnelle. Une association un-à-… ne peut se concevoir que si la partie un de l’association est garantie unique. Si cette règle est violée, c’est toute la cohérence du modèle qui est remise en question. De même, de nombreuses règles métiers impliquent l’unicité. Il ne peut y avoir qu’une seul conducteur de camion au même moment, un chèque doit porter un numéro unique et ne peut être encaissé que sur un seul compte bancaire. Un numéro ISBN ne peut être attribué qu’à un seul livre encore disponible, etc.
Dans un modèle, plusieurs types de clés sont possibles :
Primaire – la clé primaire est, parmi les clés candidates, celle qui est choisie pour représenter la clé qui garantit aux yeux du modèle, l’unicité dans l’entité. physique dans SQL Server, chaque ligne doit contenir une valeur, elle ne pourra donc pas supporter les marqueurs NULL. Elle sera le plus souvent celle qui sera déplacée en clé étrangère, dans les associations ;
candidate – la clé candidate pourrait être clé primaire. Elle est une autre façon de garantir un tuple unique. Elle n’a pas été choisie comme clé primaire soit par malchance pour elle, soit pour des raisons bassement physiques (sa taille par exemple, qui influe sur la taille des clés étrangères et potentiellement de l’index clustered – nous verrons ce concept dans le chapitre 6) ;
naturelle– par opposition à la clé technique, la clé naturelle est créée sur un attribut signifiant, qui existe dans le monde réel modélisé par le schéma. Par exemple, un numéro ISBN, un EAN13, un numéro national d’identité, un numéro de téléphone, etc. Le danger de la clé naturelle est son manque potentiel de stabilité, le fait que son format peut changer suite à une décision que vous ne maîtrisez pas, et la possibilité qu’elle soit réattribuée à travers le temps. L’avantage est que la clé elle-même est déjà signifiante ;
technique (surrogate) – la clé technique est une clé en général numérique, créée par défaut d’existence d’une clé naturelle, pour unifier les tuples. Elle est souvent implémentée physiquement avec un procédé de calcul d’autoincrément, comme un séquenceur ou la propriété IDENTITY en SQL Server. Elle a souvent tendance à devenir « naturelle » aux utilisateurs des données, qui parlent alors du client 4567 ou de la facture 3453. Si vous souhaitez vous prévenir de cette « dérive », il est bon de la cacher autant que possible dans les interfaces utilisateur ;
intelligente – la clé intelligente est une clé qui contient plusieurs informations. Elle permet donc d’extraire des contenus utiles. Par exemple, un numéro ISBN contient le numéro de zone linguistique, et le numéro d’éditeur. Le Numéro national d’identité (numéro de sécurité sociale) donne le sexe ainsi que l’année, le mois, le département et la commune de naissance. Elle peut permettre de gagner du temps aux recherches, cette logique pouvant être extraite de la clé par programmation, sans recherche dans des tables de référence (qu’il faut créer pour contrôle, mais qu’il ne sera pas toujours utile de requêter dans les extractions). Une clé intelligente peut être générée par le système avec des informations utiles. Par exemple, une clé destinée à unifier un système réparti peut contenir un identifiant de base, de serveur ou de data center ;
étrangère – clé déplacée dans une table fille, correspondant à un clé de la table mère.
Modéliser les relations
Les relations sont exprimées par des cardinalités c’est-à-dire le nombre possible de tuples de chaque côté de la relation. On en distinguent plusieurs types :
Identifiante – la clé primaire d’une table est migrée dans la clé primaire d’une autre table. Relation de un-à-un ;
non-identifiante – la clé primaire est migrée dans un attribut non-clé de la table fille. Relation de un-à-plusieurs ;
optionnelle – relation non-identifiante avec valeur non nécessaire. Relation de zéro-à-plusieurs ;
récursive – l’attribut clé est lié à un autre attribut de la même table ;
plusieurs-à-plusieurs – non-identifiant dans les deux sens. En implémentation physique, cette cardinalité nécessite une table intermédiaire.
Lorsqu’une clé est migrée plusieurs fois dans la même table fille, on parle de rôles joués par la clé.
Il est de bon aloi de préfixer le nom de l’attribut déplacé par son rôle.
Par exemple, pour un lien avec un identifiant de personne : VendeurPersonneID, et ClientPersonneID.
La normalisation
Une bon modèle de données n’exprime une information qu’une seule fois, au bon endroit. Dès que la même information est placée à deux endroits du modèle, sa valeur est compromise… parce qu’elle peut être différente. Si nous pouvons trouver le numéro de téléphone d’un contact dans la table contact, et dans la table adresse, qui lui est reliée, que faire lorsque les deux numéros ne sont pas les mêmes (et croyez-nous, tôt ou tard il y aura des différences) ? Il y a peut-être un numéro erroné, mais lequel ? Ou il s’agit simplement de son numéro privé et de son numéro professionnel… mais lequel ? Toute information doit être précisée, délimitée et unifiée, c’est le but de la normalisation.
Ce qui sous-tend le concept de normalisation, est en fin de compte, le monde réel. Il n’y a rien de particulièrement technique, il n’y à pas d’ingénierie particulièrement obscure et sophistiquées dans la modélisation de données, fort heureusement. La plupart des tentatives de complexification, surtout si elles entraîne le modèle à s’éloigner de la réalité, sont des errements malheureux. Que cela signifie-t-il ? Qu’un modèle de données relationnel est formé d’entités et de relations : des tables, et des relations entre ces tables. Chaque entité décrit une réalité délimitée, observable dans le champ modélisé par la base de données. Il suffit d’observer autour de soi, de comprendre la nature élémentaire des processus à l’œuvre, pour dessiner un modèle de données. Avons-nous des clients, des magasins, des employés, des produits ? Nous aurons donc les tables Client, Magasin, Employe, Produit. Un employé vend-il à ses clients des produits dans un magasin ? Nous aurons donc une table de vente, qui référence un vendeur, un magasin, un client, un produit, à une date donnée, avec un identifiant de vente, peut-être un numéro de ticket de caisse. Mais, vend-il plusieurs produits lors de la même vente ? Nous aurons donc à supprimer l’identifiant de produit dans la table de ventes, et à créer une table de produits vendus, liée à la vente. L’employé est-il toujours dans le même magasin ? Sans doute, alors retirons l’identifiant de magasin de la vente, et ajoutons l’identifiant du magasin dans la table des employés. Et si l’employé peut changer de magasin ? Créons alors une table intermédiaire qui lie l’employé au magasin, avec – c’est une bonne idée – des dates de validité. Vous trouverez sur la figure 4.1 un modèle très simple de ces entités.
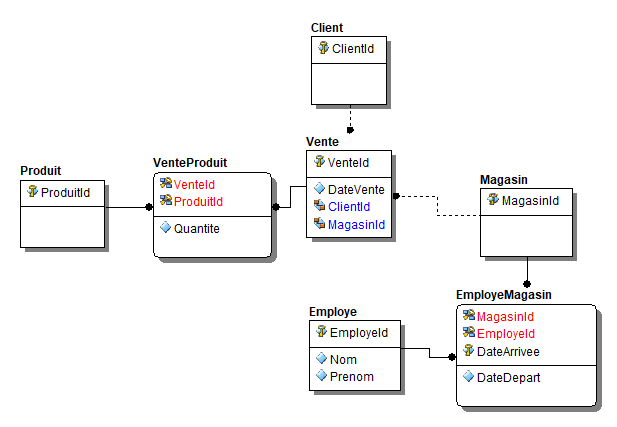
Règles métier : Puisque nous abordons l’idée de dates de validité, vous devez être extrêmement attentif lors de la phase de modélisation aux règles métier (business rules). Elles doivent être placées autant que possible dans la structure. Les règles complexes pourront être implémentées en déclencheurs (triggers).
En résumé, il faut stocker autant d’information utile possible, pour permettre de retrouver des données qui ont du sens et de la valeur, et, par conséquent peut-on dire, placer l’information au bon endroit, c’est-à-dire dans la bonne entité, celle à laquelle elle appartient naturellement, en respectant un principe important : l’économie. Cela veut dire, éviter la duplication de données, qui alourdit le modèle, conceptuellement et physiquement, et diminue les performances.
La granularité des données est aussi à prendre en compte désirez-vous des données détaillées (tout un ticket de caisse, produit par produit), ou seulement des totaux ? En général, en application OLTP, les détails sont conservés : vous en aurez forcément besoin un jour. Dans une application OLAP, on ne garde parfois que des agrégats, par exemple des totaux par jour.
Normaliser un modèle de données veut dire le rendre conformes à des règles nommées « formes normales ».
Ce qu’on appelle les formes normales sont des lois importantes de structuration du modèle de données, qui permettent de s’assurer que celui-ci évite les pièges les plus élémentaires, en assurant une base de conception favorable à un stockage utile et optimal des données. Par utile, nous entendons, favorable à l’extraction des données désirées, dans la plupart des cas de figures. Pour être complet, les formes normales principales sont au nombre de six. Toutefois, les trois premières sont les plus importantes et les plus utiles dans la « vie réelle » de la modélisation de données. Chaque forme normale complète les formes précédente. Il est donc nécessaire de les appliquer dans l’ordre.
Première forme normale (1FN) : tout attribut doit contenir une valeur atomique, c’est à dire que toutes ses propriétés doivent être élémentaires. En clair, cela signifie que vous utiliserez une colonne par pièce d’information à stocker, et qu’en aucun cas vous ne vous permettrez de colonnes concaténant des éléments différents d’information. Cette règle est importante pour deux raisons : elle va vous permettre toute la souplesse nécessaire à la restitution et à la manipulation des données, et elle va vous permettre, bien plus en aval, de vous assurez de bonnes performances. Créer le modèle d’une base de données est aussi un exercice de prudence et d’anticipation.
Ne prenez pas de décision à la légère. Si vous estimez par exemple qu’une ligne d’adresse peut être contenue dans une seule colonne (‘12, boulevard de Codd’, par exemple), êtes-vous sûr que vous n’aurez jamais besoin – donc que personne ne vous demandera jamais – d’un tri des adresses par rue et numéro de rue ?
Si vous modélisez la base de données d’un service de gestion des eaux, ne voudrez-vous pas fournir aux employés chargés de relever les compteurs une liste des habitants, dans l’ordre du numéro d’immeuble de la rue ?
Comment ferez-vous sans avoir isolé ce numéro dans un attribut (une colonne) dédié ?
Comme beaucoup, vous allez vous échiner à récupérer ce numéro avec des fonctions telles que SUBSTRING(), en prenant en compte toutes les particularités de saisie possibles.
Vous n’avez alors plus de garantie de résultats corrects, seulement celle d’une baisse de performances.
En résumé, toute valeur dont vous savez, ou soupçonnez, que vous allez devoir manipuler, afficher, chercher individuellement devra faire l’objet d’un attribut, donc être stockée dans sa propre colonne. Ne créez des colonnes contenant des types complexes que lorsque leur relation est indissociable.
Attributs de réserve : une autre réflexion : ne créez pas d’attributs inutiles. Créer des colonnes réservées à un usage ultérieur, par exemple, n’a aucun sens. Vous alourdissez le modèle et la taille de vos tables inutilement. Les versions modernes des SGBDR comme SQL Server permettent très facilement d’ajouter ou de supprimer des colonnes après création de la table. Même lorsque les objets font parties d’une réplication, il est devenu aisé, à partir de SQL Server 2005, de répliquer aussi les changements de structure. Il n’y a donc aucune justification rationnelle à créer des colonnes réservées.
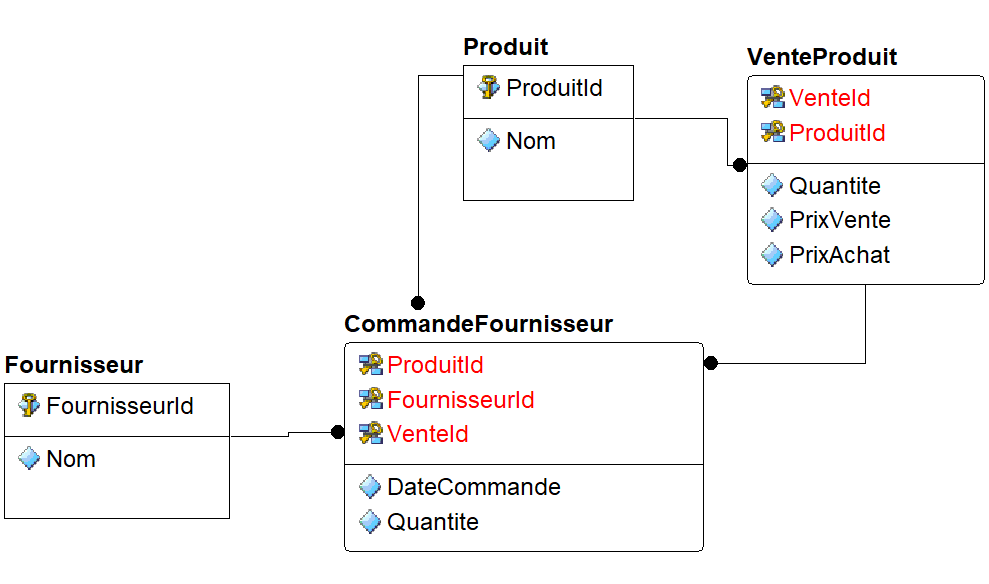
Deuxième forme normale (2FN) : L’entité doit respecter la 1FN. Tous les attributs doivent être un fait concernant la clé toute entière, et non pas un sous-ensemble de la clé. Cette forme normale concerne les entités dont la clé est composite. Dans ce cas, chaque attribut doit dépendre de tous les attributs formant la clé. Par exemple, dans notre exemple de magasin, l’entité VenteProduit représente un produit vendu lors d’un acte de vente. Sa clé est composite : une clé de produit, une clé de vente. Nous voulons connaître le prix de vente unitaire du produit, ainsi que le prix d’achat au fournisseur, pour connaître notre marge. Où devons-nous mettre ces attributs. Sur la figure 4.2,

Est-ce logique ? Le prix d’achat au fournisseur dépend-il de toute la clé, c’est-à-dire du produit et de la vente ? Certainement pas : le prix d’achat ne dépend pas de la vente effectuée, à moins que nous gérions notre stock en flux tendu, et que nous commandions le produit chez notre fournisseur à chaque commande du client. À ce moment, peut-être négoçions-nous un prix particulier selon la quantité commandée ? Alors, cela aurait peut-être du sens de placer le prix d’achat dans cette entité. Mais dépendrait-il réellement de la vente ? Si nous réalisons plusieurs ventes le même jour, et que nous effectuons une commande groupée auprès du fournisseur, il s’agit alors plus d’une notion de commande fournisseur, qui peut être liée à la vente, comme par exemple sur la figure 4.3.
Mais en faisant cela, nous rendons la clé de la vente, partie de la clé de la commande, ce qui signifie que nous ne pouvons créer de commande que pour une seule vente, nous devons donc créer une entité intermédiaire, comme à la figure 4.4.
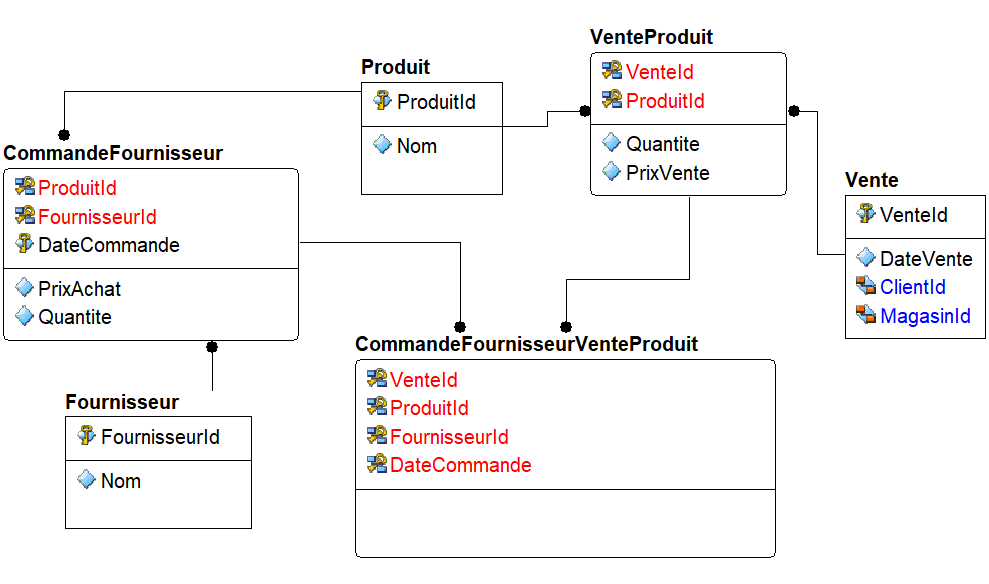
La clé qui compose l’entité CommandeFournisseurVenteProduit devient longue, c’est un problème si elle doit être répercutée dans des tables filles en tant que clé étrangère, et c’est un atout si on doit trouver rapidement à partir de cette entité, dans notre code, la référence de nos entités liées.
Prévision : dans la phase de modélisation conceptuelle, on ne réfléchit pas à l’utilité des clés par rapport aux requêtes d’extraction. Dans la modélisation physique, il devient utile, voir nécessaire de le faire, pour intégrer les performances des requêtes déjà au niveau de la modélisation – c’est l’objet de cet ouvrage. Nous pensons qu’il est très utile d’avoir en tête les facilités apportées à nos requêtes, et à notre recherche d’information, pour intégrer ces besoins et ces contraintes dans notre modélisation physique.
Malheureusement, ce modèle est loin d’être parfait.
Nous avons,
notamment, deux quantités : une quantité de produits commandés, et une
quantité de produits vendus.
Ne peut-on pas déduire le nombre de
produits commandés en additionnant le nombre de produits vendus ? Si
oui, il est important de supprimer l’attribut Quantite de l’entité
CommandeFournisseur.
Pourquoi ? Car si nous la conservons, la question
sera : où aller chercher l’information ? Si plus tard, à l’aide d’une
requête, nous trouvons une différence entre la quantité de produits
commandés et la somme des produits vendus, quelle est la quantité qui
nous donne ce qui s’est vraiment passé dans la réalité ?
En revanche, si nous n’avons que l’attribut Quantite de l’entité
VenteProduit, que se passe-t-il si une vente est annulée par le client
après que la commande soit passée, ou si le client modifie sa quantité ?
Comment savoir quelle est la quantité de produits réellement commandée ?
Ici, le modèle doit être complété : si le client modifie la quantité de
produits voulus, il nous faut un moyen d’en conserver l’historique,
peut-être en amendant la vente, ou en créant une deuxième vente liée à
la première, par une clé récursive.
Et si la vente est annulée, il nous faut certainement également un moyen d’exprimer dans notre schéma ce qu’il advient des produits commandés, afin de ne pas en perdre la trace, et de pouvoir les attribuer à des ventes ultérieures, pour gérer efficacement notre stock.
Troisième forme normale (3FN) : L’entité doit respecter la 2FN. Tous les attributs doivent être des faits concernant directement la clé, rien que la clé. Ils ne doivent en aucun cas dépendre d’un attribut non-clé. Dans notre exemple précédent, si l’entité Vente contient un attribut magasin, peut-on dire qu’il viole la 3FN ? Douteux parce que la vente a bien lieu dans un magasin ? Certes, les deux informations sont liées, mais le magasin dépend-il de la vente (la clé), et seulement de la vente ? Non, parce que dans le monde que nous modélisons, le magasin dépend aussi d’un attribut non-clé : l’employé, car nous savons que cet employé est attribué à un magasin. Il viole donc la 3FN. En ajoutant des attributs qui dépendent d’un attribut non-clé, nous sommes certains d’introduire de la redondance dans le modèle. Ici, l’identifiant de magasin n’a besoin d’être écrit une seule fois, dans l’entité Employé, et non pas à chaque vente.
Un signe courant et évident de violation de la 3NF, est la présence dans une entité d’attributs numérotés. Des attributs tels que Adresse1, Adresse2, Adresse3 peuvent à la rigueur être douloureusement acceptés, mais AdressePrivee1, AdressePrivee2, AdressePrivee3, AdresseProfessionnelle1, AdresseProfessionnelle2, AdresseProfessionnelle3, est clairement un problème. Il est temps de créer une entité Adresse, avec un attribut discriminant, spécifiant le type d’adresse. La création de « séquences » d’attributs est un cercle vicieux : vous avez l’impression d’y mettre un doigt, et bientôt vous y avez enfoncé votre bras tout entier. À chaque besoin nouveau, vous vous retrouvez à ajouter une nouvelle colonne, avec un incrément de séquence. Que ferez-vous lorsque vous en serez arrivé à la colonne Propriete20, ou Telephone12 ? Modélisez votre base correctement, ou si vous devez maintenir un modèle existant, « refactorez ».
Refactoring : le concept de refactoring indique les techniques de modification du code tout au long de son existence. Il faut, en matière de modèle de données, songer à modifier la structure lorsque des nouveaux besoin se font sentir. Il faut résister à l’envie de code en dur des modifications de logique, pour éviter de récrire ses requêtes après modification de schéma. Adapter son schéma est plus long, mais bien plus solide et évolutif.
Lorsque la base est normalisée, il est parfois utile de dénormaliser, c’est-à-dire de dupliquer au besoin – et uniquement lorsque c’est absolument nécessaire – le contenu d’une colonne. La plupart du temps, dénormaliser n’est pas nécessaire. Souvent les dénormalisations sont faites avant même de tester les performances des requêtes, ou pour résoudre des problèmes de performances qui proviennent d’une mauvaise écriture de code SQL. Même si la dénormalisation se révèle utile, des mécanismes de SQL Server comme les colonnes calculées ou les vues indexées, permettent de dupliquer logiquement les données sans risquer des incohérences. L’autre solution pour dénormaliser consiste à créer des colonnes physiques qui vont contenir des données provenant d’autres tables, et qui sont maintenues par code, en général par déclencheur ou procédure stockée. Cette approche comporte quelques inconvénients : ajouter du code augmente les risques d’erreur, diminue les performances générales et complexifie la gestion de la base. Nous vous conseillons en tout cas vivement, dans ce cas, d’utiliser une méthodologie simple, claire et consistante. Créez par exemple des déclencheurs, avec une convention de nommage qui vous permet de les identifier rapidement, et optimisez leur code.
Une chose en tout cas est importante : la dénormalisation n’est pas la règle, mais tout à fait l’exception, et elle ne doit être menée qu’en dernier ressort. En tout cas, comme son nom l’indique, elle consiste à modifier un schéma déjà normalisé. En aucun cas, elle ne peut être une façon préliminaire de bâtir son modèle.
Logiquement, plus votre modèle est normalisé, plus le nombre de tables augmente, et moins vous avez de colonne par table. Cela a de nombreux avantages de performance : vous diminuez le nombre de données dupliquées, donc le volume de votre base, vous réduisez le nombre de lectures nécessaires pour extraire un sous-ensemble de données (on cherche en général à récupérer une partie seulement des lignes et colonnes, pas une table toute entière), vous augmentez la possibilité de créer des index clustered (plus sur ce concept dans le chapitre 6), et donc la capacité à obtenir des résultats ordrés sans des opérations de tri coûteuses et à générer des plans d’exécution utilisant l’opérateur de jointure de fusion (merge join), un algorithme de jointure très rapide, etc.
Citoyens, n’ayez pas peur de la normalisation ! Ne tombez pas dans le piège consistant à croire que l’augmentation du nombre de tables va rendre votre code SQL compliqué, et va faire baisser les performances. Créer des tables qui ne respectent pas au moins les trois premières formes normales vous entraînera dans une multitude de problèmes avec lesquels vous serez obligé de vivre quotidiennement. Prenez dès le début de bonnes habitudes. En ce qui concerne la complexité, vous pouvez la dissimuler par la création de vues, qui sont, du point de vue du modèle relationnel, conceptuellement identiques aux tables.
Pour aller plus loin, nous vous conseillons de vous procurer un bon ouvrage sur la modélisation relationnelle, comme par exemple « UML 2 pour les bases de données », de Christian Soutou.
Le modèle OLAP
En 1993, Edward Codd publia un libre blanc nommé « Providing OLAP (On-line Analytical Processing) to User-Analysts: An IT Mandate », dans le but de préciser les exigences d’applications destinées à l’analyse de vastes volumes de données, ce qu’on appelle aujourd’hui de plusieurs termes : Systèmes d’aide à la décision (decision support system, DSS), business intelligence, décisionnel, etc. Malgré la légère polémique autour de cet article, commandité par Hyperion (l’entreprise s’appelait alors Arbor Software) donc peut-être partiel, sans doute plus écrit par ses collaborateurs que par Codd lui-même, et en tout cas non supporté par Chris Date, l’associé à Codd, l’écrit popularisa le terme OLAP, par opposition à OLTP. Un système OLTP (OnLine Transactional Processing) est en perpétuelle modification, les opérations qui s’y exécutent sont encapsulées dans des transactions, ce qui permet un accès multi-utilisateurs en lecture comme en écriture. C’est pour ce genre de système que le modèle relationnel, les douze lois de Codd (qui sont treize) et les formes normales furent conçus.
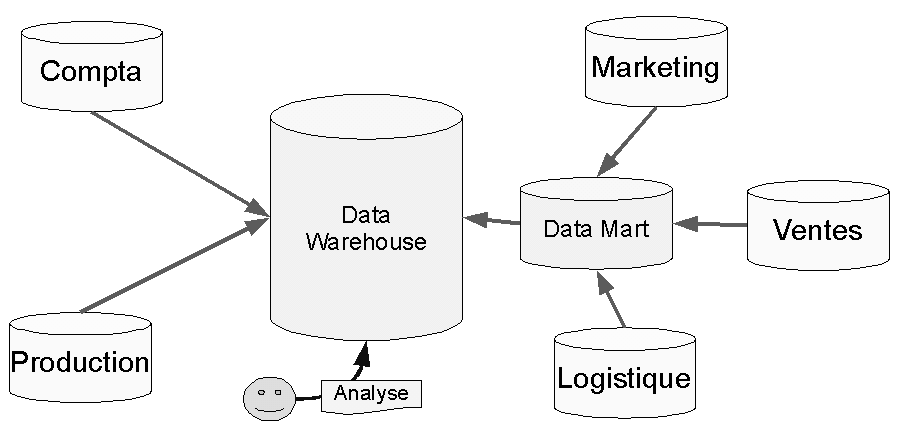
Un système OLAP (OnLine Analytical Processing) est utilisé principalement en lecture, pour des besoins d’analyse et d’agrégation de larges volumes de données. Alors que les requêtes OLTP se concentrent en général sur un nombre réduit de lignes, les requêtes analytiques doivent parcourir un grand ensemble de données pour en extraire les synthèses et les tendances. Les systèmes OLAP sont en général implémentés en relation avec des entrepôts de données (data warehouses) parfois constitués en « succursales » nommées data marts. Ces entrepôts centralisent toutes les données (opérationnelles, financières, etc.) de l’entreprise (ou du groupe) – souvent avec une perspective historique – provenant de tous les services, pour offrir une vision globale de l’activité et des performances. Ce qui est schématisé dans la figure 4.5.
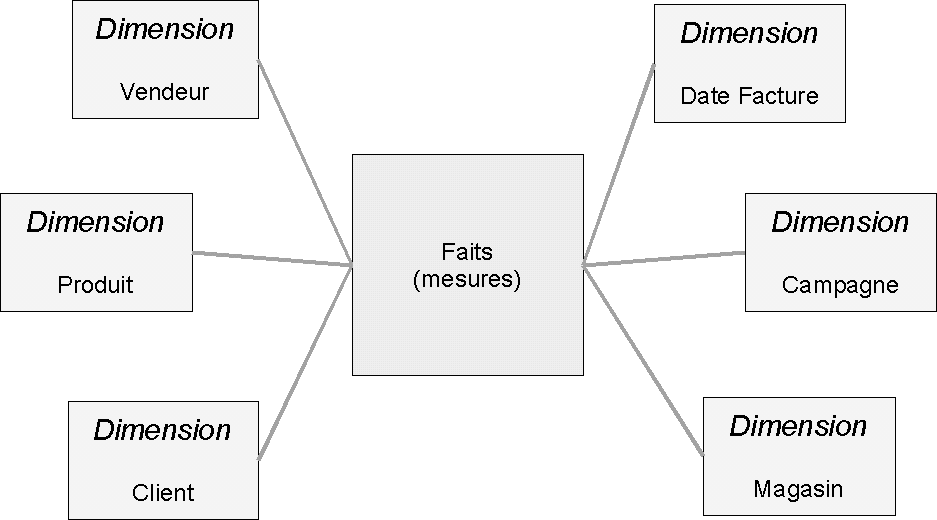
Pour faciliter l’analyse des données, une représentation dite multi-dimensionnelle, sous forme de « cubes », s’est développée. Il s’agit de présenter les indicateurs chiffrés (données de ventes, quantités, prix, ratios, etc.), qu’on appelles aussi mesures, en les regroupant sur des axes d’analyse multiples, qu’on appelle dimensions. Les agrégations (regroupements) sont effectuées à travers ces dimensions. On peut par exemple vouloir afficher les données de ventes par mois, par types de produits, sur les magasins d’un département donné, pour un fournisseur. Le modèle relationnel normalisé n’est pas optimal pour cette forme de requêtage sur des volumes très importants de données. De cette constatation, deux modèles princpaux propres à l’OLAP se sont développés : le modèle en étoile et le modèle en flocon.
Le modèle en étoile (star schema, figure 4.6), fortement dénormalisé, présente une table centrale des indicateurs (une table de faits, ou fact table), qui contient en plus des mesures, les identifiant de liaison à chaque dimension. Les tables de dimensions « entourent » la table de faits. Ces tables de dimensions peuvent contenir des colonnes fortement redondantes. On peut par exemple, dans une dimension client, avoir des colonnes Ville et Pays qui contiennent les noms de lieu en toutes lettres, dupliqués des dizaines ou des centaines de milliers de fois. Les erreurs de saisies ne peuvent pas se produire, puisque ces tables sont alimentées exclusivement par des processus automatiques, et les lectures en masse sont facilitées par l’élimination de la nécessité de suivre les jointures. La volumétrie n’est pas non plus un problème, ces systèmes étant bâtis autour de solutions de stockage adaptées.
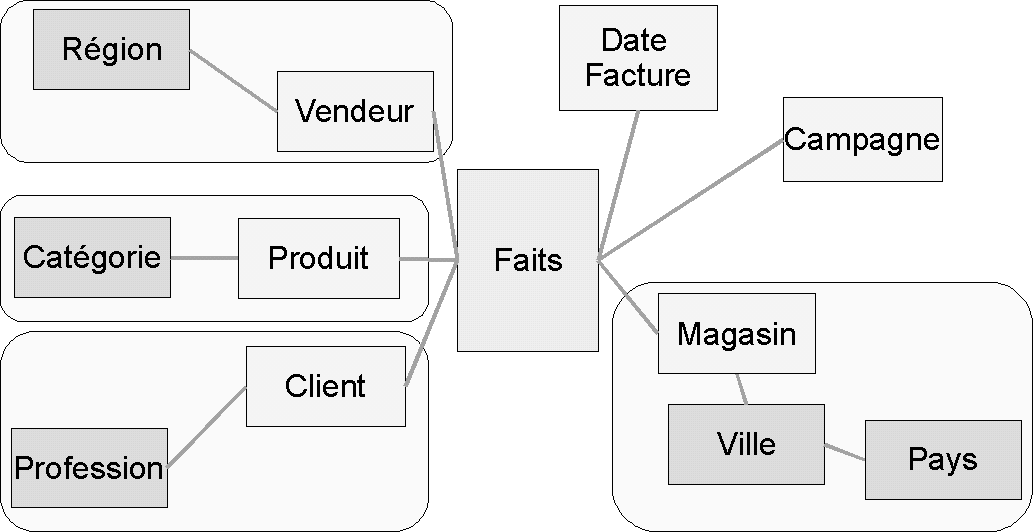
Le modèle en flocon (snowflake schema, figure 4.7) est une version du modèle en étoile qui conserve, sur certaines dimensions, des relations dans le but de limiter le volume de stockage nécessaire. Il peut être utilisé si la quantité de données dupliquées est vraiment trop importante. En général, un modèle en étoile est préférable.
Cet ouvrage se concentre sur l ‘optimisation d’un système OLTP, nous tenions toutefois à vous présenter les fondamentaux de l’OLAP afin de vous donner l’orientation nécessaire au cas où vous auriez à modéliser un entrepôt de données.
Pour aller plus loin sur le sujet, un livre fait référence : « Entrepôts de données. Guide pratique de modélisation dimensionnelle, 2ème édition », de de Ralph Kimball et Margy Ross, aux édtions Vuibert informatique (édition anglaise : The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling, chez Wiley). Ralph Kimball est un des deux théoriciens importants du décisionnel moderne, et les principes de ce livre ont été appliqués dans les outils BI de SQL Server.
bien choisir ses types de données
Lors du passage au Modèle Physique de Données (MPD), c’est-à-dire lors de l’adaptation du MCD à une implémentation de SGBDR particulière – SQL Server en ce qui nous concerne –, plusieurs considérations sont importantes pour les performances :
Choisissez les bons types de données. Nous avons vu que la 1FN nous prescrit de dédier chaque attribut à une valeur atomique. Physiquement, il est également important de dédier le type de données adapté à cette valeur. Par exemple, si vous devons exprimer un mois de l’année, faut-il utiliser un type DATE (ou DATETIME en SQL Server 2005), ou un CHAR(6), dans lequel nous inscririons par exemple ‘200801’ pour le mois de janvier 2008 ? Si l’idée vous vient d’utiliser un CHAR(6), que ferez-vous lorsqu’il vous sera demandé de retourner par requête la différence en mois entre deux dates ? Si vous avez opté dès le départ pour le type qui convient, la fonction DATEDIFF() est tout ce dont vous avez besoin. De plus, le type DATE est codé sur trois octets, alors qu’un CHAR(6), par définition, occupe le double. Sur une table de dix millions de lignes, cela représente donc un surpoids d’environ trente mégaoctets, totalement inutile et contre-performant.
Prévoir la volumétrie : à la mise en place d’une nouvelle base de données, estimez sa volumétrie future, pour dimensionner correctement votre machine, vos disques et la taille de vos fichiers de données et de journal. Vous pouvez utiliser les fonctionnalités intégrées de dimensionnement des outils de modélisation comme Embarcadero ER/Studio ou Sybase PowerDesigner / PowerAMC. HP publie aussi des outils de sizing : http://activeanswers.compaq.com/ActiveAnswers/Render/1,1027,4795-6-100-225-1,00.htm. Vous pouvez aussi créer votre propre script, par exemple basé sur la colonne max_length de la vue sys.columns, en prenant en compte que la valeur de max_length pour un objet large est -1.
Une colonne comportant un type de taille trop importante augmente la taille de la ligne, il s’ensuit que moins de lignes peuvent résider dans la même page, et plus de pages doivent être lues, ou parcourues, pour obtenir le même jeu de données. Il est important, dans ce cadre, de faire la distinction entre types précis et types approchées, types de taille fixe ou de taille variable, ainsi que les types qui restent dans la page, de ceux qui peuvent s’en échapper. Passons en revue quelques types de données système de SQL Server.
Numériques
Les types numériques sont soit entiers, soit décimaux, à virgule fixe ou
flottante.
Les types entiers sont codés en un bit (BIT), un octet
(TINYINT), deux octets (SMALLINT), quatre octets (INT) ou huit octets
(BIGINT).
Le BIT est utilisé en général pour exprimer des valeurs booléennes (vrai ou faux).
Il accepte le marqueur NULL.
Le stockage des colonnes de type BIT est optimisé par le regroupement de plusieurs de
ses colonnes dans un seul octet de stockage.
Ainsi, si vous avez de une à huit colonnes de type BIT, SQL Server utilisera un octet dans sa page de données, de neuf à seize, deux octets, etc.
Vous pouvez donc créer plusieurs de ces colonnes sans inquiétude.
Notez que les chaînes de caractères TRUE et FALSE sont convertibles en BIT, explicitement ou implicitement, ce qui est utile pour reproduire dans son code un
comportement proche d’un type booléen.
Si vous pouvez travailler directement en 0 ou 1, faites-le, cela évitera la phase de conversion :
-- ok
SELECT CAST('TRUE' as bit), CAST('FALSE' as bit)
SET LANGUAGE 'french'
-- erreur
SELECT CAST('VRAI' as bit), CAST('FALSE' as bit)
-- ok
DECLARE @bool bit
SET @bool = 'TRUE'
SELECT @bool
Une autre option est de créer une colonne de type entier ou BINARY, et y stocker des positions 0 ou 1, bit par bit (en créant une colonne utilisée comme bitmap, champ de bits). Les opérateurs T-SQL de gestion des bit (bitwise operators) vous permettent de manipuler chaque position. C’est un moyen efficace de gérer un état complexe, car il permet d’exprimer à la fois des positions particulières, et une vue générale, indexable, de la situation de la ligne. Une recherche sur un état complexe pourra profiter de cette approche, par contre, une recherche impliquant seulement une position de bits sera moins efficace. Prenons un exemple :
USE tempdb
GO
CREATE TABLE dbo.PartiPolitique (
code char(5) NOT NULL PRIMARY KEY CLUSTERED,
nom varchar(100) NOT NULL UNIQUE,
type int NOT NULL DEFAULT(0)
)
GO
INSERT INTO dbo.PartiPolitique (code, nom)
SELECT 'PCF', 'Parti Communiste Français' UNION ALL
SELECT 'MRC', 'Mouvement Républicain et Citoyen' UNION ALL
SELECT 'PS', 'Parti Socialiste' UNION ALL
SELECT 'PRG', 'Parti Radical de Gauche' UNION ALL
SELECT 'VERTS', 'Les Verts' UNION ALL
SELECT 'MODEM', 'Mouvement Démocrate' UNION ALL
SELECT 'UDF', 'Union pour la Démocratie Française' UNION ALL
SELECT 'PSLE', 'Nouveau Centre' UNION ALL
SELECT 'UMP', 'Union pour un Mouvement Populaire' UNION ALL
SELECT 'RPF', 'Rassemblement pour la France' UNION ALL
SELECT 'DLR', 'Debout la République' UNION ALL
SELECT 'FN', 'Front National' UNION ALL
SELECT 'LO', 'Lutte Ouvrière' UNION ALL
SELECT 'LCR', 'Ligue Communiste Révolutionnaire'
GO
CREATE INDEX nix$PartiPolitique$type
ON dbo.PartiPolitique ([type])
GO
-- à droite
UPDATE dbo.PartiPolitique
SET type = type | POWER(2, 0)
WHERE code in ('MODEM', 'UDF', 'PSLE', 'UMP', 'RPF', 'DLR',
'FN', 'CPNT')
-- à gauche
UPDATE dbo.PartiPolitique
SET type = type | POWER(2, 1)
WHERE code in ('MODEM', 'UDF', 'PS', 'PCF', 'PRG', 'VERTS', 'LO', 'LCR')
-- antilibéral
UPDATE dbo.PartiPolitique
SET type = type | POWER(2, 2)
WHERE code in ('PCF', 'LO', 'LCR')
-- au gouvernement
UPDATE dbo.PartiPolitique
SET type = type | POWER(2, 3)
WHERE code in ('UMP', 'PSLE')
-- qui est au centre ?
-- scan
SELECT code
FROM dbo.PartiPolitique
WHERE type & (1 | 2) = (1 | 2)
-- seek...
mais incorrect
SELECT code
FROM dbo.PartiPolitique
WHERE type = 3
Le deux dernières requêtes utilisent deux stratégies de recherche différentes. Elle produisent un plan d’exécution très différent également, car la première requête ne peut pas utiliser d’index pour l’aider. Reportez-vous à la section 6.2 traitant du choix des index, pour avoir plus de détails.
Vous pouvez aussi créer une table de référence indiquant quelle est la valeur de chaque bit, et gérer dans votre code des variables de type INT pour exprimer lisiblement quelles sont les valeurs de chaque bit. Mais dans cet ouvrage dédié aux performances, nous devons préciser que ces méthodes sont souvent une facilité de code qui diminue la performance des requêtes.
En règle général, une clé technique, autoincrémentale (IDENTITY) ou non,
sera codée en INT.
L’entier 32 bits permet d’exprimer des valeurs jusqu’à 2^31-1 (2 147 483 647), ce qui est souvent bien suffisant.
Si vous avez besoin d’un peu plus, comme les types numériques sont signés, vous pouvez disposer de 4 294 967 295 valeurs en incluant les nombres
négatifs dans votre identifiant.
Vous pouvez aussi indiquer le plus grand nombre négatif possible comme graine (seed) de votre propriété IDENTITY, pour permettre à la colonne autoincrémentale de profiter de cette plage de valeurs élargie :
CREATE TABLE dbo.autoincrement (id int IDENTITY(-2147483648, 1)).
Pour les identifiants de tables de référence, un SMALLINT ou un TINYINT
peuvent suffire.
Il est tout à fait possible de créer une colonne de ces
types avec la propriété IDENTITY.
N’oubliez pas que les identifiants sont en général les clés primaires des tables. Par défaut, la clé primaire est clustered (voir les index clustered en section 6.1). L’identifiant se retrouve donc très souvent clé de l’index clustered de la table. La clé de l’index clustered est incluse dans tous les index nonclustered de la table, et a donc une influence sur la taille de tous les index. Plus un index est grand, plus il est coûteux à parcourir, et moins SQL Server sera susceptible de l’utiliser dans un plan d’exécution.
Chaînes de caractères
Les chaînes de caractères peuvent être exprimées en CHAR ou en VARCHAR pour les chaînes ANSI, et en NCHAR ou NVARCHAR pour les chaînes Unicode.
Un caractère Unicode est codé sur deux octets.
Un type Unicode demandera donc deux fois plus d’espace qu’un type ANSI.
La taille maximale d’un (VAR)CHAR est 8000.
La taille maximale d’un N(VAR)CHAR, en toute logique, 4000.
La taille du CHAR est fixe, celle du VARCHAR variable.
La différence réside dans le stockage.
Un char sera toujours stocké avec la taille déclarée à la création de la variable ou de la colonne, et un VARCHAR ne stockera que la taille réelle de la chaîne.
Si une valeur inférieure à la taille maximale est insérée dans un CHAR, elle sera
automatiquement complétée par des espaces (caractère ASCII 32).
Ceci concerne uniquement le stockage, les fonctions de chaîne de T-SQL et les comparaisons appliquant automatiquement un RTRIM au contenu de variables et de colonnes.
Démonstration :
DECLARE @ch char(20)
DECLARE @vch varchar(10)
SET @ch = '1234'
SET @vch = '1234 ' -- on ajoute deux espaces
SELECT ASCII(SUBSTRING(@ch, 5, 1)) -- 32 = espace
SELECT LEN (@ch), LEN(@vch) --- les deux donnent 4
IF @ch = @vch
PRINT 'c''est la même chose' --- eh oui, c'est la même chose
SELECT DATALENGTH (@ch), DATALENGTH(@vch) -- @vch = 6, les espaces sont présents.
SET @vch = @ch
SELECT DATALENGTH(@vch) --- 2 !
Ce comportement est toujours valable dans le cas de chaînes Unicode, ou si on mélange des chaînes Ansi avec des chaînes Unicode, sauf dans le cas du LIKE ! Dans ce cas, les espaces finaux sont importants.
Il s’agit d’une conformité avec la norme SQL-92 (implémentée seulement pour l’Unicode…) :
DECLARE @vch varchar(50)
DECLARE @nvch nvarchar(100)
SET @vch = 'salut !'
SET @nvch = 'salut !'
IF @vch = @nvch PRINT 'ok'; -- ça marche...
IF @vch LIKE @nvch PRINT 'ok' -- ça ne marche pas...
Donc, utilisez les '%' pour obtenir des résultats conformes à vos
attentes dans ces cas.
Qu’en est-il donc de l’utilité du RTRIM dans la récupération ou
l’insertion de données ?
Le RTRIM est inutile dans un traitement de CHAR, puisque le moteur de stockage ajoute de toute manière des espaces pour compléter la donnée.
En revanche, pour l’insertion ou l’affichage de VARCHAR, un RTRIM peut être utile si vous soupçonnez que les chaînes insérées peuvent contenir des espaces.
Comme nous le voyons dans l’exemple, les espaces explicites à la fin d’une chaîne, sont conservées dans le VARCHAR.
Cela inclut le cas où vous copiez une valeur d’un type CHAR vers un type VARCHAR : les espaces sont conservés.
Méfiez-vous de ne pas alourdir inutilement vos tables en oubliant ce détail lors de l’import ou de l’échange de données.
Note : Ce comportement correspond au cas où l’option
SET ANSI_PADDINGétait activée lors de la création de la colonne ou de la variable. Cette option est par défaut àON, et il est recommandé de la laisser ainsi, pour garantir un comportement cohérent des colonnes, en accord avec la norme SQL.
Vous pouvez vérifier vos colonnes de type VARCHAR avec une requête comme celle-ci :
SELECT
AVG(DATALENGTH(EmailAddress)) as AvgDatalength,
AVG(LEN(EmailAddress)) as AvgLen,
SUM(DATALENGTH(EmailAddress)) - SUM(LEN(EmailAddress)) as Spaces,
COLUMNPROPERTY(OBJECT_ID('Person.Contact'),
'EmailAddress', 'precision') as ColumnLength
FROM Person.Contact;
qui vous donne le remplissage moyen de la colonne, contre la taille moyenne réelle, et la différence en octets totaux.
Attention, cette requête n’est valable que pour les colonnes Ansi, divisez DATALENGTH() par deux, dans le cas de colonnes Unicode.
Comment connaître les colonnes de taille variable dans votre base de données ? Une requête de ce type va vous donner la réponse :
SELECT
QUOTENAME(TABLE_SCHEMA) + '.' + QUOTENAME(TABLE_NAME) as tbl, QUOTENAME(COLUMN_NAME) as col,
DATA_TYPE + ' (' +
CASE CHARACTER_MAXIMUM_LENGTH
WHEN -1 THEN 'MAX'
ELSE CAST(CHARACTER_MAXIMUM_LENGTH as VARCHAR(20))
END + ')' as type
FROM INFORMATION_SCHEMA.COLUMNS
WHERE DATA_TYPE LIKE 'var%' OR DATA_TYPE LIKE 'nvar%'
ORDER BY tbl, ORDINAL_POSITION;
Vous pouvez aussi utiliser la fonction COLUMNPROPERTY().
En conclusion, la règle de base est assez simple : utilisez le plus petit type de données possible. Si votre colonne n’a pas besoin de stocker des chaînes dans des langues nécessitant l’Unicode (chinois, japonais, etc.) créez des colonnes ANSI. Elles seront raisonnablement valables pour toutes les langues utilisant un alphabet latin.
Elles vous feront économiser 50 % d’espace.
Certains outils Microsoft ont tendance à créer automatiquement des colonnes Unicode.
N’hésitez pas à changer cela à l’aide d’un ALTER TABLE par exemple.
Il n’y a pratiquement aucun risque d’effet de bord dans votre code SQL, à part l’utilisation de DATALENGTH ou de LIKE, comme nous l’avons vu ci-dessus.
La différence de temps d’accès par le moteur de stockage entre une colonne fixe ou variable, en termes de recherche de position de la chaîne, est négligeable, par contre, la différence de volume de données à transmettre lors d’un SELECT, peut impacter les performances.
Comme règle de base, n’utilisez des CHAR que pour des longueurs inférieures à 10 octets, et de préférence sur des colonnes dont vous êtes sûrs de stocker toujours la même taille de chaîne (par exemple, pour une colonne de codes ISO de pays, ne créez pas un VARCHAR(2), mais un CHAR(2), car le VARCHAR crée deux octets supplémentaires pour le pointeur qui permet d’indiquer sa position dans la ligne).
Évitez les CHAR de grande taille, vous risquez de remplir inutilement votre fichier de données.
Imaginons que vous créiez une table ayant un CHAR(5000) ou un NCHAR(2500), vous auriez ainsi la garantie que chaque page de données ne peut contenir qu’une ligne.
Si vous ne stockez que dix caractères dans cette colonne, vous avec besoin, pour dix octets, d’occuper en réalité 8060 octets…
Inversement, des colonnes variables peuvent provoquer de la fragmentation dans les pages ou dans les extensions, selon que les mises à jour modifient la taille de la ligne.
Donc, songez à tester régulièrement la fragmentation, et à défragmenter vos tables lorsque nécessaire.
Nous aborderons ce point dans le chapitre 6.
Valeurs temporelles
La plupart des bases de données doivent stocker des données temporelles.
Jusqu’à SQL Server 2008, vous disposiez de deux types de données seulement : DATETIME et SMALLDATETIME.
Ne faites pas de confusion avec TIMESTAMP, qui, dans SQL Server, contrairement à d’autres SGBDR et à la norme SQL, ne correspond pas à un type de données de date, mais à un compteur unique par base de données, incémenté automatiquement à la modification de toute colonne portant ce type de données.
DATETIMEest codé sur huit octets, quatre octets stockant la date, et quatre l’heure.SMALLDATETIMEest codé sur quatre octets, deux octets stockant la date, et deux l’heure.
Cela permet au type DATETIME de couvrir une période allant du 1 janvier 1753 au 31 décembre 9999, avec une précision de la partie heure de 3,33 millisecondes.
Le type SMALLDATETIME va du 1 janvier 1900 au 6 juin 2079, avec une précision à la minute.
Le type SMALLDATIME est deux fois plus court que le type DATETIME, il est donc à préférer tant que possible.
Il est idéal pour exprimer toute date/heure dont la granularité est au-dessus de la minute.
Si vous devez stocker des temps plus précis, comme par exemple des lignes de journalisation, n’utilisez surtout pas SMALLDATETIME, il vous serait impossible de trier correctement les lignes à l’intérieur de la même minute.
Il fut un temps où certains langages client, comme Visual Basic, ne manipulaient pas correctement le type SMALLDATETIME.
Ce temps est révolu depuis longtemps.
Le type DATETIME est plus précis, mais pas exactement précis.
Méfiez-vous de son arrondi : Vous pouvez passer, en chaîne de caractères, une valeur de temps en millisecondes, qui sera arrondie automatiquement par SQL Server, et cela peut vous réserver des surprises.
Imaginez que votre application cliente soit précise à la milliseconde, et insère deux lignes, à deux millisecondes près.
Pour SQL Server, la valeur DATETIME sera la même.
Démonstration :
DECLARE @date1 datetime
DECLARE @date2 datetime
SET @date1 = '20071231 23:59:59:999'
SET @date2 = '20080101 00:00:00:001'
IF @date1 = @date2
PRINT 'pas de différence'
Pour SQL Server, Ces deux dates correspondent au 1 janvier 2008, minuit exactement (2008-01-01 00:00:00.000).
Attention donc également aux comparaisons.
Puisque les types DATETIME et SMALLDATETIME contiennent toujours la partie heure, une comparaison doit se faire aux 3 millisecondes, ou à la minute près.
C’est un problème récurrent de performances, car il faut souvent convertir la valeur de la colonne pour lui donner l’heure 00:00:00.000 dans la clause WHERE, ce qui empêche toute utilisation d’index.
Si vous savez que vous avez ce type de recherche à faire, stockez systématiquement vos DATETIME avec la partie horaire à 0, ou créez une colonne calculée indexée qui reprend la date seulement, et recherchez sur cette colonne.
Si vous êtes en SQL Server 2008, vous avez plus de choix.
SQL Server 2008 ajoute plusieurs nouveaux types de données temporels :
DATE– stocke seulement la date, sur trois octets ;TIME– stocke seulement la partie horaire.TIMEest beaucoup plus précis que la partie heure d’unDATETIME. Sa plage de valeurs va de00:00:00.0000000à23:59:59.9999999. Sa précision est donc de 100 nanosecondes, sur trois à cinq octets ;DATETIME2: stocké sur huit octets,DATETIME2permet une plus grande plage de valeurs queDATETIME. Sa plage de dates va de0001-01-01à9999-12-31, avec une précision de temps maximale (donc paramétrable) à 100 nanosecondes. Si vous diminuez la précision, vous pouvez stocker unDATETIME2sur six octets. Ce nouveau type a été introduit principalement par compatibilité avec les dates .NET, et avec la norme SQL ;DATETIMEOFFSET: basé sur unDATETIME2,DATETIMEOFFSETajoute une zone horaire. Codé sur huit à dix octets.
Note : Pour éviter les problèmes en rapport avec les formats de dates liés aux langues, passer les dates en ISO 8601 non séparé :
'AAAAMMJJ'.
Type XML
SQL Server 2005 a introduit le type de données XML, qui fait partie de la norme SQL:2003. Une colonne ou variable XML peut contenir jusqu’à 2 Go d’instance XML bien formé ou valide, codé en UTF-16 uniquement. Une colonne XML peut être validée par une collection de schéma XSD (un schéma, dans le monde XML, est la description de la structure d’un document XML. Le sujet en soi mériterait un ouvrage).
Voici un exemple de création de collection de schémas :
CREATE XML SCHEMA COLLECTION
[Person].[AdditionalContactInfoSchemaCollection]
AS N'<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
...
</xsd:schema>'
Le schéma se voit dans la vue système sys.xml_schema_collections, ou
dans l’explorateur d’objets de SSMS, dans une base de données, dans le
dossier Programmability/Types/XML Schema Collections.
On l’appelle une collection de schémas, parce que plusieurs schémas peuvent être utilisés, de façon complémentaire, pour valider le même document ou fragment.
Vous pouvez ensuite créer une table qui contient une colonne de type XML, validée par cette collection de schémas :
CREATE TABLE [Person].[Contact](
[ContactID] [int] IDENTITY(1,1) NOT NULL,
-- ...
[AdditionalContactInfo]
[xml]([Person].[AdditionalContactInfoSchemaCollection]) NULL
);
Nous obtenons alors une colonne XML typée, par opposition à une colonne non validée par un schéma, dite non typée. La collection de schémas est une contrainte de colonne, au même titre qu’une contrainte CHECK, par exemple.
On pourrait se dire que la validation par le schéma est une étape supplémentaire effectuée par le moteur, et qu’elle est donc nuisible au performances.
En réalité, c’est le contraire.
²
Comme pour la contrainte CHECK, la vérification est effectuée à l’écriture dans la colonne (et selon la complexité de la collection de schémas, cette étape peut se révéler coûteuse), mais on lit en général plus souvent que l’on écrit, et ensuite, à l’extraction, SQL Server pourra s’appuyer sur les informations fournies par la contrainte, pour faciliter son travail.
Le schéma fournit des informations précises sur le type de données des items dans le XML, ce qui permet à SQL Server de stocker l’instance XML sous une forme binaire (un blob XML) au lieu d’une représentation textuelle, ce qui rend la colonne XML beaucoup plus compacte.
Les valeurs atomiques sont aussi stockées avec leur type de données (l’information de type est donnée dans la collection de schéma), ce qui permet un parsing beaucoup plus efficace. Enfin, la vérification de la validité d’une requête XQuery par rapport aux types de valeurs peut être vérifiée à sa compilation, et des optimisations peuvent être effectuées. Le typage améliore aussi l’efficacité des index XML[^10]. Bref, cherchez autant que possible à créer des colonnes XML typées.
Vous pouvez indexer vos colonnes XML, ce qui crée une représentation interne en table relationnelle, et crée un index B-Tree sur cette structure.
Pour plus d’information sur la structure des index, reportez-vous à la section 6.1.
Types divers
Il existe un type de données dont nous ne devrions même pas parler ici, tant il est à éviter : sql_variant. Comme son nom l’indique, il correspond à un variant dans les langages comme Visual Basic, c’est-à-dire qu’il adapte automatiquement son type par rapport à la valeur stockée. C’est évidemment une type à éviter absolument, tant par son impact sur les performances que par son laxisme en terme de contraintes de données. Le type sql_variant peut contenir 8016 octets, il est donc indexable à vos risques et périls (une clé d’index supérieure à 900 octets générera une erreur). On ne peut le concaténer, ni l’utiliser dans une colonne calculée, ou un LIKE… Bref, oubliez-le.
Le type de données UNIQUEIDENTIFIER correspond à un GUID (Globally Unique Identifier), une valeur codée sur 16 octets générée à partir d’un algorithme qui la rend unique à travers le monde et au delà (le GUID n’est pas garanti unique per se, mais les probabilités que deux GUID identiques puissent être générés sont statistiquement infinitésimales). Vous voyez des GUID un peu partout dans le monde Microsoft, notamment dans la base de registre. On entend en général par le terme GUID, l’implémentation par Microsoft de la norme UUID (Universally Unique Identifier), qui calcule notamment une partie de la chaîne avec la MAC Address de l’ordinateur. Un exemple de GUID : CC61D24F-125B-4347-BB37-9E7908613279.
Certaines personnes l’utilisent pour générer des clés primaires de tables, profitant de l’unicité globale du GUID pour obtenir une clé unique à travers différentes tables ou bases de données, ou pour générer des identifiants non séquentiels, par exemple pour un identifiant d’utilisateur sur une application Web, et ainsi éviter qu’un pirate ne devine l’Id d’un autre utilisateur. En termes de performances, utiliser un UNIQUEIDENTIFIER en clé primaire est une très mauvaise idée, à plus forte raison si l’index sur la clé est clustered. Cela tient bien sûr à la taille de la donnée (vous verrez dans le chapitre 6 que tous les index incorporent la clé de l’index clustered). C’est aussi un excellent moyen de fragmenter la table : si vous créez un index clustered sur une colonne où les données s’insèrent à des positions aléatoires, vous provoquez une intense activité de séparation de pages (les pages doivent se séparer et déplacer une partie de leurs lignes ailleurs, pour accommoder les nouvelles lignes insérées, plus de détails dans le chapitre sur les index), donc une baisse de performances, et une forte fragmentation… donc un baisse de performances. Enfin, cela a de fortes chances d’augmenter significativement la taille de votre base, puisqu’une clé primaire est souvent déplacée dans plusieurs tables filles en clés étrangères. Tout cela faisant 16 octets par clé, le stockage est plus lourd, les index plus gros, et les jointures plus coûteuses pour les requêtes.
Si vous songez à utiliser des GUIDs dans une problématique de bases de données dispersées, optez plutôt pour une clé primaire composite, à deux colonnes : une colonne donnant un identifiant de serveur ou de base de données, et l’autre identifiant un compteur IDENTITY propre à la table. Vous aurez non seulement l’information de la base source de la ligne dans la clé, mais de plus celle-ci pèsera 5 ou 6 octets (un TINYINT ou SMALLINT pour l’id de base, un INT pour l’id de ligne) au lieu de 16.
Vous générez les valeurs de GUID dans vos colonnes UNIQUEIDENTIFIER à l’aide de la fonction T-SQL NEWID(), que vous pouvez placer dans la contrainte DEFAULT de la colonne.
Si vous devez utiliser un
UNIQUEIDENTIFIER et que vous voulez l’indexer, vous pouvez utiliser
(seulement en contrainte DEFAULT) la fonction NEWSEQUENTIALID(), qui
génère un GUID plus grand que tous ceux présents dans la colonne.
Cette
fonction a été créée pour éviter la fragmentation.
Toutefois, si vous
l’utilisez, vous perdez l’avantage de la génération aléatoire, et un
pirate intelligent pourra facilement deviner des GUID précédents.
Dans
les problématiques d’identifiant web, il vaut mieux programmer dans
l’application cliente un algorithme de génération de hachage à partir
des identifiants de la base de données, pour les protéger des curieux.
Cela permet de conserver de bonnes performances du côté SQL Server.
Objets larges
SQL Server proposait les types TEXT, NTEXT et IMAGE, pour stocker respectivement des objets larges de type chaînes ANSI et Unicode, et des objets binaire, comme des documents en format propriétaire, des fichiers image ou son. Ces types sont toujours à disposition, mais ils sont obsolètes et remplacés par (N)VARCHAR(MAX) et VARBINARY(MAX). Comme leurs anciens équivalents, ils permettent de stocker juqu’à 2 Go de données (2^31-1 octets, précisément), mais leur comportement est sensiblement différent. Ces types sont ce qu’on appelle des LOB (Large Objects, objets larges), bien que dans les BOL, vous verrez utilisé le nom « valeurs larges » (large values) pour les nouveaux types (le type XML en fait aussi partie). Ils sont stockés à même le fichier de données, dans des pages de 8 Ko, organisés d’une façon particulière.
Les types TEXT, NTEXT et IMAGE, conformément à leur comportement en SQL Server 2000, posent dans la ligne de la table un pointeur de 16 octets sur une structure externe à la page. Cette structure est organisée en arbre équilibré (B-Tree), comme un index, pour permettre un accès rapide aux différentes positions à l’intérieur du LOB. Lors de toute restitution de la ligne, le moteur de stockage doit donc suivre ce pointeur et récupérer ces pages, même si la colonne ne contient que quelques octets. En SQL Server 2000, nous avions un moyen de forcer SQL Server à stocker dans la page elle-même le contenu du LOB, s’il ne dépassait pas une certaine taille, à l’aide de la procédure stockée sp_tableoption. Cette option existe toujours sur SQL Server 2005, et elle peut être utile pour optimiser des colonnes (N)TEXT. Par exemple :
EXEC sp_tableoption nomtable 'text in row', taille;
où taille est la taille en octets des données à inclure dans la page, dans une plage allant de 24 à 7000 (la chaîne ‘ON’ est aussi acceptée, elle correspond à une taille de 256 octets). Dès que cette option est activée, si le contenu de la colonne est inférieur à la taille indiquée, il est inséré dans la page, comme une valeur traditionnelle. Pourquoi la limite inférieure est-elle de 24 octets ? Simplement parce que, quand ’text in row’ est activé, le moteur de stockage ne pose plus de pointeur vers la structure LOB. Si la donnée insérée est plus grande que la taille maximum spécifiée, il inscrira dans la page la racine de la structure B-Tree du LOB, qui pèse... 24 bits.
Pour désactiver cette option, il suffit de donner la taille à 0, ou ‘OFF’ (attention, cela force la conversion de tous les BLOBs existants, ce qui peut prendre un certain temps selon la cardinalité de la table).
Cette opération n’étant utile que pour les colonnes de type (N)TEXT et IMAGE, nous ne nous y attarderons pas. Utilisez les nouveaux types. Ceux-ci gèrent automatiquement l’inclusion dans la ligne lorsque le contenu peut tenir dans la page (à concurrence de 8000 octets), en agissant alors comme un VARCHAR. S’il ne peut tenir dans la page, il est déplacé dans une structure LOB, et agit donc comme un objet large. Le terme « MAX » permet d’assurer l’évolution vers des tailles de LOB supérieures dans les versions futures de SQL Server sans modifier la définition des tables. Ce fonctionnement représente le meilleur des deux mondes.
Une autre option de table gère le comportement des valeurs larges ((N)VARCHAR(MAX), VARBINARY(MAX) et XML) :
EXEC sp_tableoption nomtable 'large value types out of row', ['ON'|'OFF'];
ON (1) – Le contenu est toujours stocké dans une structure LOB, la page ne contient que le pointeur à 16 octets.
OFF (0) – Le contenu est stocké dans la page s’il peut y tenir.
Il s’agit donc du raisonnement inverse de ’text in row’. ON ici veut dire que le LOB est toujours extérieur à la page. La valeur par défaut est OFF. Vous pouvez inspecter les valeurs des deux options pour vos tables, avec la vue système sys.tables :
SELECT SCHEMA_NAME(schema_id) + '.' + Name as tbl,
text_in_row_limit,
large_value_types_out_of_row
FROM sys.tables
ORDER BY tbl;
Il peut être intéressant de mettre ’large value types out of row’ à ON, au cas par cas. Si une table comporte une colonne de valeur large (un XML par exemple) qui stocke des structures qui ne sont que très peu retournées dans les requêtes d’extraction, activer cette option permet de conserver des pages plus compactes, et donc d’optimiser la plupart des lectures qui ne demandent pas le LOB.
Lorsque l’option ’large value types out of row’ est changée, dans un sens ou dans l’autre, les lignes existantes ne sont pas modifiées. Elles le seront au fur et à mesures des UPDATE.
Dépassement de ligne
Dans le chapitre concernant la structure du fichier de données, nous avons dit qu’il n’était pas possible, pour une ligne, de dépasser 8060 octets, qui est l’espace disponible dans une page de données de 8 Ko. Nous venons de voir que le stockage des LOB permet de s’affranchir de cette limite. Pour autant, ce stockage comporte des inconvénients : la structure en B-Tree de gestion des LOB est un peu lourde lorsqu’il s’agit de gérer des valeurs qui vont jusqu’à 8 Ko, mais qui ne peuvent tenir dans la page à cause de la taille des autres colonnes. Une solution à ce problème pourrait être de partitionner verticalement, en créant une autre table contenant une colonne VARCHAR(8000) et l’identifiant, pour une relation un-à-un sur la première table. À partir de SQL Server 2005, ce n’est plus nécessaire, un mécanisme automatique permet aux colonnes de longueur variable de dépasser la limite de la page. Cette fonctionnalité est appelée « dépassement de page » (row overflow), elle ne s’applique qu’aux types variables : (N)VARCHAR et VARBINARY. Les types de données .NET peuvent aussi en profiter. Prenons un exemple simple :
USE tempdb
GO
CREATE TABLE dbo.longcontact (
longcontactId int NOT NULL PRIMARY KEY,
nom varchar(5000),
prenom varchar(5000)
)
GO
INSERT INTO dbo.longcontact (longcontactId, nom, prenom)
SELECT 1, REPLICATE('N', 5000), REPLICATE('P', 5000)
GO
Avant SQL Server 2005, la création de cette table aurait été acceptée, mais avec l’affichage d’un avertissement disant que l’insertion d’une ligne dépassant 8060 octets ne pourrait aboutir. Et dans les faits, l’INSERT aurait déclenché une erreur. En SQL Server 2005, tout fonctionne comme un charme. Observons ce qui a été stocké :
SELECT p.index_id, au.type_desc, au.used_pages
FROM sys.partitions p
JOIN sys.allocation_units au ON p.partition_id = au.container_id
WHERE p.object_id = OBJECT_ID('dbo.longcontact');
Donc, l’insertion s’est déroulée sans problème, pour une ligne d’une taille totale de 10004 octets (2x 5000, plus 4 octet d’INTEGER). À l’insertion, SQL Server a automatiquement déplacé une partie de la ligne dans une autre page, créée à la volée, qui sert uniquement à continuer la ligne. Cette page est d’un type spécial, comme nous l’avons vu dans la requête sur sys.allocation_units. Alors que la ligne est normalement dans une page de type In-row data, le reste doit être placé dans une page de type Row-overflow data.
Nous voyons qu’il y a quatre pages en tout, dont deux pages de row overflow. Pourquoi deux pages, alors que nous n’avons ajouté que de quoi remplir une seule page de dépassement ? Vérifions à l’aide de DBCC IND :
DBCC IND ('tempdb', 'longcontact', 1);
Nous voyons le résultat sur la figure 4.8.

Fig. 4.8 – résultat de DBCC IND
Pour chaque type de page, nous avons une page de type 10, c’est-à-dire une page IAM (Index Allocation Map), en quelque sorte la table des matières du stockage. Tout s’explique.
Essayons maintenant ceci :
UPDATE dbo.longcontact
SET prenom = 'Albert'
WHERE longcontactId = 1;
Et relançons la requête sur sys.allocation_units. Nous n’avons plus que trois pages : l’IAM et la page de données pour l’allocation In-row data, et seulement l’IAM pour l’allocation Row-overflow data. La page de row overflow a été supprimée, toute la ligne est revenue dans la page. La page d’IAM n’a pas été supprimée, elle pourra être réutilisée au prochain dépassement.
SQL Server ne remet pas toujours la colonne dans la page In row lorsque la valeur diminue. Il ne vérifie que la nouvelle valeur peut tenir dans la page que si elle a diminué d’au moins 1000 octets, ce qui lui évite de trop fréquentes vérifications.
Essayons autre chose :
TRUNCATE TABLE dbo.longcontact
GO
INSERT INTO dbo.longcontact (longcontactId, nom, prenom)
SELECT 2, REPLICATE('N', 5000), REPLICATE('P', 3100)
INSERT INTO dbo.longcontact (longcontactId, nom, prenom)
SELECT 3, REPLICATE('N', 5000), REPLICATE('P', 3100)
GO
Ici, nous forçons l’insertion de deux nouvelles lignes qui vont générer du dépassement, mais avec un remplissage de colonnes qui peut faire tenir deux lignes dans la même page In-row... que va faire SQL Server. Il va créer en effet une seule page In-row, et déplacer les deux colonnes nom dans deux pages de row overflow. Il faut noter que les pages de row overflow contiennent des valeurs entières. Une colonne ne peut pas être réparties sur plusieurs pages. C’est pour cette raison que le row overflow s’applique à des types variables limités à une taille de 8000 octets (et à une taille minimum de 24 octets, qui est l’espace nécessaire pour stocker le pointeur vers la page de row overflow).
Cela nous amène à une dernière question : une page de row overflow peut-elle partager des données venant de plusieurs lignes, ou faut-il une nouvelle page pour chaque ligne qui est en dépassement ? La seconde solution augmenterait le volume de stockage de façon potentiellement importante. Vérifions ce qui se passe, à l’aide d’une table légèrement modifiée :
CREATE TABLE dbo.troplongcontact (
troplongcontactId int NOT NULL PRIMARY KEY,
nom char(8000),
prenom varchar(5000)
)
GO
INSERT INTO dbo.troplongcontact (troplongcontactId, nom, prenom)
SELECT 2, REPLICATE('N', 8000), REPLICATE('P', 1000)
INSERT INTO dbo.troplongcontact (troplongcontactId, nom, prenom)
SELECT 3, REPLICATE('N', 8000), REPLICATE('P', 1000)
GO
Ici, nous ne conservons qu’une seule colonne de taille variable, nous nous assurons donc de générer du row overflow que sur cette colonne.
Que nous dit un DBCC IND ? Nous voyons le résultat sur la figure 4.9.

Fig. 4.9 – résultat de DBCC IND
Nous voyons quatre pages In row, et deux pages Data overflow, de différents DataTypes. Ceux qu’on voit ici sont
- 1 – page de données ;
- 2 – page d’index ;
- 3 – page de LOB ;
- 10 – IAM.
Il y a donc deux pages de données In Row, et une page LOB. Observons la page LOB à l’aide de DBCC PAGE :
DBCC TRACEON (3604)
DBCC PAGE (tempdb, 1, 127, 3)
Dans le résultat, nous trouvons ceci :
Blob row at: Page (1:127) Slot 0 Length: 1014 Type: 3 (DATA)\
Blob Id:9306112
...
Blob row at: Page (1:127) Slot 1 Length: 1014 Type: 3 (DATA)\
Blob Id:1128660992
La longueur correspond à nos 1000 octets, plus quelques octets supplémentaires. CQFD.
La fonctionnalité de row overflow est bien pratique, mais qu’en est-il des performances ? Elles sont nécessairement moins bonnes. À chaque lecture de page, le moteur de stockage doit aller chercher ailleurs d’autres pages pour lire les données si des colonnes en row overflow sont demandées, ce qui provoque des lectures aléatoires (random IO) supplémentaires. De plus, comme les pages de row overflow contiennent la totalité de la valeur d’une colonne, cela génère souvent de la fragmentation interne : les pages ne sont pas remplies de façon optimale. En un mot, réservez le row overflow à des cas limités, pour gérer un éventuel dépassement de page, pour des colonnes qui sont en général compactes mais peuvent de temps en temps contenir une chaîne plus longue.
Les statistiques de pages lues, retournées par SET STATISTICS IO ON, et la trace SQL, affichent différemment les pages lues. La trace SQL montre, dans la colonne reads, le nombre total de pages lues (In row, Row overflow et LOB Data), y compris les pages d’IAM. Les statistiques IO renvoyées dans la session séparent les pages In row des pages Row overflow et LOB. Exemple de statistiques retournées pour une table contenant 2 pages In row, 2 pages de row overflow, et 3 pages de LOB (VARCHAR(MAX)), pages IAM comprises :
Table ‘bigcontact’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 5, lob physical reads 0, lob read-ahead reads 0.
L’utilisation de SET STATISTICS IO ON permet donc d’obtenir des résultats plus précis.
FILESTREAM
Le type FILESTREAM est nouveau dans SQL Server 2008. C’est une implémentation du type de données DATALINK de la norme SQL. SQL server n’est pas prévu pour gérer efficacement le stockage et la manipulation d’objets larges, et maintenir des LOB en grandes quantité pose des problèmes de performances. Souvent, pour éviter ces problèmes, nous stockons les fichiers sur le système de fichiers, et référençons le chemin dans une colonne varchar. Le problème avec cette approche est qu’il faut en général ouvrir un partage sur le réseau, maintenir ces fichiers d’une façon ou d’une autre, et gérer les sauvegardes de ces fichiers en plus des sauvegardes SQL.
En gérant des types FILESTREAM, vous créez un groupe de fichiers particulier pour les stocker, et ce groupe de fichiers utilise un stockage NTFS, plus adapté, plutôt que le stockage traditionnel des fichiers de données. La cohérence transactionnelle sur ces fichiers est aussi assurée.
Pour utiliser FILESTREAM, vous devez d’abord activer la fonctionnalité, à l’aide de sp_configure :
EXEC sp_configure 'filestream_access_level', '[niveau d'activation]'
RECONFIGURE
et de SQL Server Configuration Manager (voir figure 4.10)

Fig. 4.10 – configurer FILESTREAM
ou de la procédure stockée sp_filestream_configure, qui prend deux paramètres : @enable_level et @share_name. @enable_level indique le niveau d’activation :
- 0 – désactivé ;
- 1 – activé pour T-SQL uniquement : pas d’accès des fichiers directs hors de SQL Server ;
- 2 – activé aussi pour l’accès direct aux fichiers, en accès local seulement ;
- 3 – activé aussi pour l’accès direct aux fichiers à travers un partage réseau.
@share_name permet de spécifier un nom de partage réseau, qui est celui de l’instance SQL Server par défaut. Ensuite, lancez la commande RECONFIGURE pour que les changements soient pris en compte.
Cette procédure va peut-être disparaître à la sortie définitive de SQL Server 2008, et être remplacée par une option d’installation de l’instance. Voir http://www.sqlskills.com/blogs/bobb/2008/02/28/ConfiguringFilestreamInCTP6ItsDifferent.aspx et les BOL si vous avez des problèmes à sa mise en œuvre. De plus, dans la version beta, un redémarrage de l’instance est souvent nécessaire pour activer cette fonction. Cela pourrait être amélioré à la sortie finale.
Vous créez ensuite un groupe de fichiers destiné au FILESTREAM :
ALTER DATABASE AdventureWorks
ADD FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
ALTER DATABASE AdventureWorks
ADD FILE
( NAME = N'AdventureWorks_media',
FILENAME = N'E:\sqldata\AdventureWorks_media')
TO FILEGROUP [FileStreamGroup1]
GO
Ce fichier crée en réalité un répertoire à son emplacement, comme nous le voyons sur la figure 4.11.

Fig. 4.11 – répertoire des fichiers FILESTREAM
Puis, vous créez une table contenant une colonne de type FILESTREAM :
CREATE TABLE dbo.document (
documentId uniqueidentifier NOT NULL ROWGUIDCOL
DEFAULT (NEWID()) PRIMARY KEY NONCLUSTERED ,
nom varchar(1000) NOT NULL,
document varbinary(max) FILESTREAM
);
Le GUID (uniqueidentifier ROWGUIDCOL) est nécessaire pour la gestion du FILESTREAM par le moteur de stockage. Terminons par un exemple de code, qui vous montre l’insertion, et l’extraction à partir du FILESTREAM. Notez la méthode PathName() :
INSERT INTO dbo.document (nom, document)
SELECT 'babaluga', CAST('plein de choses à dire' as varbinary(max))
SELECT
nom,
CAST(document as varchar(max)) as document,
document.PathName()
FROM dbo.document
Volume de données : attention au nombre de fichiers stockés dans les répertoires FILESTREAM. À partir de quelques centaines de milliers de fichiers, des lenteurs sérieuses peuvent se faire sentir. La source du problème peut être le scan du répertoire à chaque ajout de fichier, pour générer un nom en format 8.3 lié. Vous pouvez désactiver ce comportement dans NTFS à l’aide de l’exécutable fsutil :
fsutil behavior set disable8dot3 1
Vous devez redémarrer la machine pour que ceci soit pris en compte.
Partitionnement
Mathématiquement, l’augmentation de la taille de votre base de données entraîne une diminution des performances en lecture et en écriture. Grâce à la grande qualité des techniques d’optimisation mises en œuvre dans les SGBDR modernes, et à condition que votre modèle de données soit intelligemment construit, cette augmentation de temps de réponse n’est en rien linéaire. SQL Server peut retrouver avec une grande vélocité quelques lignes dans une table qui en compte des millions. Toutefois, il n’y a pas de miracle : augmentation de taille signifie multiplication des pages de données et d’index, donc plus de lectures et plus de temps pour parcourir les objets.
Pour pallier à cette inflation de taille, vous pouvez partitionner vos tables. Le partitionnement consiste à séparer physiquement des structures, soit pour en paralléliser le traitement, soit pour retirer des lectures une partie des données moins souvent sollicitée. Le partitionnement peut soit porter sur des lignes, on l’appelera alors horizontal, soit sur des colonnes, et il sera vertical.
Le partitionnement horizontal est très souvent utile dans le cas de tables comportant un attribut temporel, par exemple une table de journalisation, de mouvements comptables, de factures, d’actes ou d’opérations diverses. Très souvent les écritures se font sur des dates récentes, et la grande majorité des lectures concerne une période limitée, par exemple aux quelques dernières années. En SQL Server 2000, nous traitions ce problème en créant des tables supplémentaires qui dupliquaient la structure de la table originale, par exemple à l’aide d’un ordre SELECT INTO, qui permet de créer une table et d’y insérer le résultat d’un SELECT à la volée. Il est tout à fait possible de continuer à utiliser cette technique dans SQL Server 2005/2008. Voici un exemple qui utilise la structure de contrôle TRY CATCH qui n’existe que depuis la version 2005[^11] :
BEGIN TRANSACTION
BEGIN TRY
SELECT *
INTO Sales.SalesOrderHeader_Archive2002
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = 2002
DELETE
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = 2002
COMMIT TRANSACTION
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
END CATCH
Vous pouvez simplifier cet exemple à partir de 2005 à l’aide de l’instruction DELETE …
BEGIN TRANSACTION
BEGIN TRY
SELECT
0 as SalesOrderID, RevisionNumber, OrderDate, DueDate, ShipDate
INTO Sales.SalesOrderHeader_Archive2002
FROM Sales.SalesOrderHeader
WHERE 1 = 2[^12]
DELETE
FROM Sales.SalesOrderHeader
OUTPUT DELETED.SalesOrderID, DELETED.RevisionNumber,
DELETED.OrderDate, DELETED.DueDate, DELETED.ShipDate
INTO Sales.SalesOrderHeader_Archive2002
WHERE YEAR(OrderDate) = 2002
COMMIT TRANSACTION
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
END CATCH
Que faire de cette nouvelle table d’archive ? Vous pouvez modifier vos applications clientes pour ajouter par exemple un bouton de recherche sur les archives, qui lance une requête SELECT sur cette table au lieu de la table originelle. Mauvaise solution. La bonne réponse est : créez une vue, qui agrège les différentes tables par des UNION ALL, et effectuez la requête sur cette vue :
CREATE VIEW Sales.vSalesOrderHeaderWithArchives
AS
SELECT
SalesOrderID, RevisionNumber, OrderDate, DueDate,
ShipDate, 0 as Source
FROM Sales.SalesOrderHeader
UNION ALL
SELECT
SalesOrderID, RevisionNumber, OrderDate, DueDate,
ShipDate, 2002 as Source
FROM Sales.SalesOrderHeader_Archive2002
Ici, pour déterminer dans nos requête de quelle table source provient chaque ligne, nous ajoutons une colonne générée dans la vue.
Vous pouvez ensuite modifier votre requête pour effectuer la recherche sur cette vue, ou prévoir deux types de recherche : une recherche sur la table originelle, et une recherche sur toute l’étendues des données, en prévenant vos utilisateurs que la recherche simple est plus rapide, mais ne comporte que des valeurs récentes.
La recherche simple sera-t-elle plus rapide ? Par forcément. Si nous lui en donnons les moyens, l’optimiseur de SQL Server est capable de savoir si la requête que nous lançons sur cette vue concerne bien toutes les tables, ou si l’accès à une des tables suffit. Comment cela ? En plaçant une contrainte CHECK sur la structure des tables sous-jacentes.
Pour illustrer la différence que va amener cet ajout, commençons par analyser les tables affectées par cet ordre SQL :
SET STATISTICS IO ON
GO
SELECT *
FROM Sales.vSalesOrderHeaderWithArchives
WHERE OrderDate BETWEEN '20020301' AND '20020401';
Nous voulons les commandes passées en mars 2002…
Résultat des statistiques IO :
(305 row(s) affected)
Table 'SalesOrderHeader_Archive2002'.
Scan count 1, logical reads 18...
Table 'SalesOrderHeader'.
Scan count 1, logical reads 700...
Donc, 18 pages lues pour SalesOrderHeader_Archive2002, 700 pages lues pour SalesOrderHeader.
Nous avons créé la table Sales.SalesOrderHeader_Archive2002 pour qu’elle ne contienne que les lignes dont l’OrderDate est compris dans l’année 2002. La table Sales.SalesOrderHeader ne contient donc plus que des lignes dont l’OrderDate est différent de 2002. Exprimons cela en contraintes CHECK sur la colonne OrderDate :
ALTER TABLE Sales.SalesOrderHeader
WITH CHECK ADD CONSTRAINT chk$SalesOrderHeader$OrderDate CHECK
(OrderDate NOT BETWEEN '20020101' AND '20021231 23:59:59.997');
GO
ALTER TABLE Sales.SalesOrderHeader_Archive2002
WITH CHECK ADD CONSTRAINT chk$SalesOrderHeader_Archive2002$OrderDate
CHECK (OrderDate BETWEEN '20020101' AND '20021231 23:59:59.997');
Le WITH CHECK n’est pas nécessaire, car la vérification de la contrainte sur les lignes existantes est effectuée par défaut. Nous désirons simplement mettre l’accent sur le fait que la contrainte doit être reconnue comme étant appliquée sur les lignes existantes, pour que l’optimiseur puisse s’en servir.
Relançons le même ordre SELECT, et observons les statistiques de lectures :
Table 'SalesOrderHeader_Archive2002'.
Scan count 1, logical reads 18…
Seule la table SalesOrderHeader_Archive2002 a été affectée. Grâce à la contrainte que nous avons posée, l’optimiseur sait avec certitude qu’il ne trouvera aucune ligne dans Sales.SalesOrderHeader correspondant à la fourchette de dates demandée dans la clause WHERE. Il peut donc éliminer cette table de son plan d’exécution.
En utilisant les contraintes CHECK, vous pouvez manuellement partitionner horizontalement vos tables, les rejoindre dans une vue, et ainsi augmenter vos performances de lecture sans sacrifier aux fonctionnalités.
Cette technique conserve un désavantage : l’administration (création de tables d’archive) reste manuelle. À partir de SQL Server 2005, des fonctions intégrées de partitionnement horizontal de table et d’index simplifient l’approche.
Partitionnement intégré
Les fonctionnalités de partitionnement sont disponibles sur SQL Server 2005 dans l’édition Entreprise seulement.
Tout ce que nous venons de faire manuellement, et plus encore, est pris en charge par le moteur de stockage. Depuis SQL Server 2005, une couche à été ajoutée dans la structure physique des données, entre l’objet et ses unités d’allocation : la partition. L’objectif premier du partitionnement est de placer différentes parties de la même table sur différentes partitions de disque, afin de paralléliser les lectures physiques et de diminuer le nombre de pages affectées par un scan ou par une recherche d’index.
La lecture en parallèle sur plusieurs unités de disques n’est vraiment intéressante, bien entendu, que lorsque les partitions sont situées sur des disques physiques différents, et de préférence sur des bus de données différents, ou sur une baie de disques ou un SAN, sur lequel on a soigneusement organisé les partitions. Chaque disque physique n’ayant qu’une seule tête de lecture, il ne sert à rien de compter sur un simple partitionnement logique sur le même disque : les accès ne pourront se faire qu’en série. De plus, l’intérêt ne sera réel que pour des VLDB (bases de données de grande taille). En effet, dans les bases de données de taille moyenne, les lectures sur le disque devraient être autant que possible évitée par une quantité suffisante de RAM pour contenir déjà la plupart des pages sollicitées dans le buffer, et éviter ainsi tout accès aux disques.
Mais même en RAM, il peut être intéressant de n’attaquer qu’une partie de la table. Un autre intérêt du partitionnement est la simplicité et la rapidité avec laquelle on peu ajouter ou retirer des partitions de la table. Nous allons le voir en pratique.
Le partitionnement se prépare avant la création de la table, il ne peut se faire sur une table existante. Pour appliquer un partitionnement à des données déjà présentes, il faut les migrer vers une nouvelle table, partitionnée. De plus, l’opération ne peut se faire en SQL Server 2005 que par code T-SQL. SQL Server 2008 propose un assistant (clic droit sur la table dans l’explorateur d’objet, menu Storage à partir de la CTP 6 de février 2008), mais pour rester compatible avec les deux versions, nous vous présentons ici les commandes T-SQL.
Pour partitionner, vous devez suivre les étapes suivantes dans l’ordre :
Créer autant de groupes de fichiers que vous désirez créer de partitions ;
Créer une fonction de partitionnement (partition function). Elle indique sur quel type de données et pour quelles plages de valeurs, les partitions vont être créées ;
Créer un plan de partitionnement (partition scheme) (traduit dans l’aide en français par « schéma » de partionnement). Il attribue chaque partition déclarée dans la fonction, à un group de fichiers ;
Créer une table qui se repose sur le plan de partitionnement.
Le partitionnement consiste à placer chaque partition sur son propre groupe de fichiers. Vous devez donc préalablement créer tous vos groupes de fichiers. Si vous cherchez à partitionner une très grande table pour optimiser les lectures physiques, faites au moins en sorte que les fichiers dans lesquels vous allez placer les lignes les plus souvent requêtées se trouvent sur des disques physiques différents.
USE Master;
ALTER DATABASE AdventureWorks ADD FILEGROUP fg1;
ALTER DATABASE AdventureWorks ADD FILEGROUP fg2;
ALTER DATABASE AdventureWorks ADD FILEGROUP fg3;
GO
ALTER DATABASE AdventureWorks
ADD FILE
( NAME = data1,
FILENAME = 'c:\temp\AdventureWorksd1.ndf',
SIZE = 1MB, maxsize = 100MB, FILEGROWTH = 1MB)
TO FILEGROUP fg1;
ALTER DATABASE AdventureWorks
ADD FILE
( NAME = data2,
FILENAME = 'c:\temp\AdventureWorksd2.ndf',
SIZE = 1MB, maxsize = 100MB, FILEGROWTH = 1MB)
TO FILEGROUP fg2;
ALTER DATABASE AdventureWorks
ADD FILE
( NAME = data3,
FILENAME = 'c:\temp\AdventureWorksd3.ndf',
SIZE = 1MB, maxsize = 100MB, FILEGROWTH = 1MB)
TO FILEGROUP fg3;
Ceci étant fait, créons une fonction de partitionnement pour notre table SalesOrderHeader :
USE AdventureWorks;
CREATE PARTITION FUNCTION pfOrderDate (datetime)
AS RANGE RIGHT
FOR VALUES ('20020101', '20030101');
Nous passons en paramètre le type de données sur lequel la fonction de partitionnement s’applique, nous indiquons aussi si les plages vont être créées pour des valeurs situées à gauche ou à droite des frontières exprimées. Ici, par exemple, la dernière partition va contenir tous les OrderDate plus grands que le 01/01/2003, c’est-à-dire à droite de cette valeur.
Cette fonction déclare donc trois partitions : tout ce qui vient avant la première valeur, tout ce qui est entre ‘20020101’ et ‘20030101’, puis tout ce qui est à droite de ‘20030101’.
Ce que nous pouvons vérifier grâce aux vues de métadonnées :
SELECT
pf.name, pf.type_desc, pf.boundary_value_on_right,
rv.boundary_id, rv.value, pf.create_date
FROM sys.partition_functions pf
JOIN sys.partition_range_values rv ON pf.function_id = rv.function_id
ORDER BY rv.value;
Pour attribuer les partitions aux groupes de fichiers, nous créons un plan de partitionnement :
CREATE PARTITION SCHEME psOrderDate
AS PARTITION pfOrderDate
TO (fg1, fg2, fg3);
Il nous reste ensuite à créer la table. Il suffit de récupérer le script de création de la table Sales.SalesOrderHeader et de le modifier légèrement :
CREATE TABLE [Sales].[SalesOrderHeader_Partitionne](
[SalesOrderID] [int] IDENTITY(1,1) NOT NULL,
--...
[ModifiedDate] [datetime] NOT NULL DEFAULT (getdate())
) ON psOrderDate(OrderDate);
Comme vous le voyez, au lieu de créer la table sur un groupe de fichiers, nous la créons sur le plan de partitionnement. Nous donnons en paramètre la colonne sur laquelle le partitionnement aura lieu, ce qu’on appelle la clé de partitionnement. Cette clé ne peut être composite : elle doit être contenue dans une seule colonne. Pour que cet exemple fonctionne, nous devons « tricher » et supprimer la clé primaire, car nous ne pouvons pas aligner notre index unique sur le partitionnement de la table. Nous reviendrons sur cette problématique quand nous aborderons le sujet des index dans le chapitre 6. Disons simplement ici que les index peuvent être aussi partitionnés. Par défaut, les index suivent le même plan de partitionnement que la table, ils sont dits « alignés ». Mais ils peuvent aussi être partitionnés différemment, ou n’être pas partitionnés et résider intégralement sur un seul groupe de fichiers. Ce choix explicite doit être indiqué dans l’instruction de création de l’index, comme nous le voyons dans le code ci-dessus.
Alimentons ensuite la table :
INSERT INTO Sales.SalesOrderHeader_Partitionne
(
RevisionNumber, OrderDate, DueDate, ShipDate, Status,
OnlineOrderFlag, PurchaseOrderNumber,
AccountNumber, CustomerID, ContactID, SalesPersonID,
TerritoryID, BillToAddressID,
ShipToAddressID, ShipMethodID, CreditCardID,
CreditCardApprovalCode, CurrencyRateID,
SubTotal, TaxAmt, Freight, Comment, rowguid, ModifiedDate
)
SELECT
RevisionNumber, OrderDate, DueDate, ShipDate,
Status, OnlineOrderFlag, PurchaseOrderNumber,
AccountNumber, CustomerID, ContactID, SalesPersonID,
TerritoryID, BillToAddressID,
ShipToAddressID, ShipMethodID, CreditCardID,
CreditCardApprovalCode, CurrencyRateID,
SubTotal, TaxAmt, Freight, Comment, rowguid, ModifiedDate
FROM Sales.SalesOrderHeader;
Nous pouvons voir ensuite comment les lignes ont été attribuées aux partitions, soit par les vues système d’allocation :
SELECT
object_name(object_id) AS Name,
partition_id,
partition_number,
rows,
allocation_unit_id,
type_desc,
total_pages
FROM sys.partitions p JOIN sys.allocation_units a
ON p.partition_id = a.container_id
WHERE object_id=object_id('Sales.SalesOrderHeader_Partitionne')
ORDER BY partition_number;
Cette requête est d’utilité publique, et peut être utilisée pour toute table, même non partitionnée. Elle permet de connaître les attributions de pages selon les différents types (type_desc) : IN ROW DATA – Ligne à l’intérieur de la page ; LOB DATA – objet large ; ROW OVERFLOW DATA – Ligne partagée sur plusieurs pages (voir section 4.1.2).
Soit, directement dans la table, en utilisant une fonction particulière retournant, pour chaque ligne, dans quelle partition elle se trouve, ce qui nous permet de tester le respect des plages :
SELECT
COUNT(*) as cnt,
MAX(OrderDate) as MaxDate,
MIN(OrderDate) as MinDate,
$PARTITION.pfOrderDate(OrderDate) AS Partition
FROM Sales.SalesOrderHeader_Partitionne
GROUP BY $PARTITION.pfOrderDate(OrderDate)
ORDER BY Partition;
Le partitionnement permet des facilités d’administration non négligeables. Ajouter, supprimer, déplacer, séparer ou joindre des partitions peut être pris en charge très rapidement à l’aide des instructions dédiées SWITCH, MERGE et SPLIT. Il n’entre pas dans le cadre de cet ouvrage de vous présenter en détail leur utilisation. Voici pour exemple comment déplacer une partition sur une autre table (existante) :
ALTER TABLE Sales.SalesOrderHeader_Partitionne
SWITCH PARTITION 1
TO Sales.SalesOrderHeader_Old;
Ces opérations sont pratiquement instantanées, car elle agissent directement au niveau du stockage de la partition, et non pas en déplaçant les lignes d’une table à une autre. Elle permettent ainsi une administration extrêmement efficace, par exemple pour un archivage régulier.
Attention : la création d’index non alignés empêchent l’utilisation de ces instructions. On ne peut pas déplacer une partition si un index non aligné existe sur la table. Dans notre exemple de partitionnement, si nous avions créé une clé primaire sur la colonne SalesOrderID, nous aurions dû la faire nonclustered et non-alignée, comme ceci :
CONSTRAINT [PK_SalesOrderHeader_Partitionne_SalesOrderID] PRIMARY KEY NONCLUSTERED (SalesOrderID) ON [PRIMARY]. Cela nous aurait empêché de réaliser desSWITCHaprès coup.
Enfin, grâce à la possibilité de réaliser des sauvegardes de fichiers ou de groupes de fichiers, la partitionnement de table permet d’optimiser vos stratégies de backup.